
HTML5 基础内容
欢迎各位小伙伴来到Web前端开发的第一站,期待与各位小伙伴共度这一旅程!视频中所有的文档、资料,都可以直接在视频下方简介中找到,视频非培训机构出品,纯个人录制,不需要加任何公众号、小程序,直接自取即可。
教程开始之前,提醒各位小伙伴:
- 如果你对某样东西不熟悉,请务必保证跟视频中使用一模一样的环境、一模一样的操作方式去使用,不要自作主张,否则出现某些奇怪的问题又不知道怎么办,就会浪费很多时间。
- 在学习过程中,尽可能避免出现中文文件夹,包括后面的环境安装、项目创建,都尽量不要放在中文路径下(因为使用中文常常出现奇奇怪怪的问题)建议使用对应的英文单词代替,或者是用拼音都可以,最好只出现英文字母和数字。
- 本系列教程统一使用 WebStorm 作为集成开发环境,该软件是免费使用的。
- 请不要抱着应试教育的心态进行学习,学习编程开发是为了掌握技能,而不是单纯为了过考试。
如果觉得本视频对你有帮助,请一键三连支持一下UP主~
互联网与Web
计算机自1946年问世以来,几乎改变了整个世界。
在信息技术迅猛发展的今天,获取信息的方式与过去相比发生了翻天覆地的变化。传统的信息获取方式主要依赖书籍、报刊和其他纸质媒体,而现代人则通过互联网和浏览器快速获取各种信息。这一转变不仅改变了我们获取知识的方式,也影响了我们的思维方式和沟通方式。
- 传统的信息交流方式: 依靠书籍、报纸、以及信件等实体介质进行传输,成本高,获取速度慢,且需要花费大量的时间查找和阅读。
- 现代化的信息交流方式: 依靠计算机,用户可以随时随地访问全球范围内的信息资源,包括但不限于网站、App、小程序、短视频等。
可见,诸如电脑手机这样的智能化设备,成为了我们现在了解信息的主要方式。
什么是网站
在科技飞速发展的今天,互联网上有着各种各样的网站,比如我们购物的淘宝、京东,搜索资料的百度、Bing,查看新闻的微博,刷视频的抖音、快手、B站等。可见我们的生活中无时无刻都会用到网站,它已经成为我们日常中不可缺少的一部分,而我们学习Web前端开发的主要方向就是网站开发。
作为用户,我们往往都是通过浏览器来打开一个网站,比如我们的官网:https://www.itbaima.cn
我们在浏览器输入网站地址后,就可以跳转到对应的网站,接着浏览器就会逐步加载网站里面的内容,直到为我们呈现出一个完整的页面,而这样的页面,我们就称其为 “网页”,网页中可以包含文本、图片、视频、音频和各种多媒体元素,并且可以自由进行排版和布局,从而展现给用户一个精美的页面。
一个网站往往包含多个网页用于呈现不同的内容,而打开网站为用户呈现的第一页,我们就称其为 “首页”,比如我们官网的首页就是对网站的整体介绍,而用户可以通过顶部的导航栏跳转到其他的页面,来访问网站的不同模块,如课程视频列表,课程文档等。
要制作出这样一个有模有样的网站,就不得不谈到一个网页的重要组成部分了:
- HTML(超文本标记语言):HTML用于定义网页的结构和内容。它通过使用标签(如
<h1>、<p>、<a>等)来组织文本和其他媒体元素。 - CSS(层叠样式表):CSS用于控制网页的外观和布局。它可以设置字体、颜色、间距、边框等样式,使网页更具视觉吸引力。
- JavaScript(脚本):JavaScript是一种编程语言,用于为网页添加交互性和动态功能。它可以响应用户的操作,比如点击按钮、提交表单等。
简单来说,HTML就像网站的骨架,也就是最基本的外形,而CSS则是在骨架的基础上对我们的页面进行美化,让页面变得更好看,JavaScript则是继续在页面的基础上添加用户的交互操作,如点击按钮等功能。这也是我们前端课程新手村必学的**“三件套”**,编写一个网站,实际上就是去编写这三件套的代码。
网站还分为静态网站和动态网站:
- 静态网站: 是指网页的内容在服务器上是固定的,用户访问时服务器直接返回这些固定的 HTML 文件。每次访问相同的页面,用户看到的内容都是一样的。
- 动态网站: 是指网页内容是动态生成的,通常依赖于数据库和服务器端脚本。用户访问时,服务器根据用户的请求或其他因素生成网页内容。
而市面上大多数商业网站都是动态网站,比如我们需要实时展示商品列表,用户的购物车等数据,这是静态网站无法做到的,而要实现动态网站,上面所说“三件套”缺一不可。
浏览器介绍
经过前面的学习我们知道,浏览器是我们访问和浏览一个网站的主要工具,这一节我们就来详细了解一下浏览器。
浏览器(Web Browser)是用于访问和展示互联网内容的应用软件。它的起源可以追溯到1980年代末,随着万维网(World Wide Web)的发展而逐渐形成。1989年,蒂姆·伯纳斯-李(Tim Berners-Lee)在CERN提出了万维网的概念,并开发了第一个网页浏览器——WorldWideWeb(后来更名为Nexus)

现如今,市面上有着非常多的浏览器,其中有着领导地位的浏览器为以下4个:
-
Internet Explorer (1995):微软推出的浏览器,随着Windows 95的发布而免费使用,迅速占领市场,逐渐取代早期的Netscape Navigator浏览器,但是目前已经被淘汰。
互联网时代的产品,用户体验感永远是排在第一位的。IE浏览器6.0版本这一用就是5年,直到2006年才升级了IE7,实际上除了更卡点,体验不到其他区别。直到2011年微软推出IE9才有较大进步,但“IE速度慢”的观念已经深入人心,微软也无力回天,后来索性使用Edge浏览器将其取代,并内置到新的Windows10和11操作系统中。
-
Safari (2003):苹果公司推出的浏览器,基于开源的WebKit引擎。
-
Firefox (2004):Mozilla基金会发布的浏览器,因其快速、安全和扩展性吸引了大量用户。
-
Google Chrome (2008):谷歌推出的浏览器,基于开源的Chromium项目,以快速和安全著称,逐渐成为最受欢迎的浏览器。
现目前,在MacOS和iOS平台上,Safari为用户主要使用的浏览器,而Windows上基本都是Edge浏览器为主,安卓主要以Chrome或是基于Chrome同款内核的第三方厂商浏览器为主。
不同浏览器有着不同的内核,浏览器内核是浏览器的核心组件,负责解释和渲染网页内容,也就是处理我们编写的HTML、CSS、JavaScript代码,并最终呈现出对应的页面。所以,没有浏览器内核,浏览器就只是一个空壳。目前市场上主要的浏览器内核有以下几款:
- Chromium / Blink
- 浏览器:Google Chrome、Microsoft Edge、Opera、360浏览器、夸克浏览器等
- 特点:Blink是在WebKit的基础上发展而来的,专注于速度和效率,尤其是它的JS执行性能非常给力,支持现代Web标准,更新速度快,能够及时响应市场需求。
- WebKit
- 浏览器:Safari
- 特点:WebKit最初是作为KDE项目的一部分开发的,后来被Apple采用并进行扩展,对于iOS设备的网页渲染,WebKit是官方推荐的内核,以其高效和节能著称,特别是在移动设备上。
- Gecko
- 浏览器:Mozilla Firefox
- 特点:Gecko是一个开源项目,致力于支持开放的Web标准,Firefox通过量身定制的功能和隐私保护机制吸引用户,同时支持多种操作系统,不限于Windows、macOS和Linux。
- Trident(已被淘汰)
- 浏览器:Internet Explorer、360浏览器兼容模式等
- 特点:Trident是微软为Internet Explorer开发的渲染引擎,随着Edge的推出,Trident逐渐被淘汰,但仍在某些老旧系统中使用,在Web标准支持方面相对较差,许多现代网页可能无法正确渲染。
不同的浏览器内核各有特点与优势,随着Web技术的发展,各个内核也在不断进化,以满足现代网页的需求。这里建议各位小伙伴统一使用Chrome作为浏览器进行开发,因为它的内核使用率目前来说是最广泛的。
Chrome浏览器官方下载地址:https://www.google.com/chrome/
Web标准
前面我们了解了多种不同的浏览器以及内核,不知道大家是否有思考过,我们编写的网页在不同浏览器下展示出来会不会出现不一样的页面呢?为了解决这种问题,我们就需要一个统一的标准来进行约束。
Web标准是指一系列的规范和技术,用于确保互联网内容(如网页和应用程序)能够在不同的设备、浏览器和平台上良好运行和显示。这些标准由各种组织制定和维护,旨在提高Web的互操作性、可访问性和开发效率。这样,所有的浏览器厂商虽然可以自行研发不同的内核,但是只要按照同一个标准来对页面进行渲染和处理,就不会出现不同浏览器展示的页面不一样的问题。
一个Web标准的主要组成部分:
- HTML(超文本标记语言):用于创建网页的结构和内容。
- CSS(层叠样式表):用于控制网页的外观和布局。
- JavaScript:用于增强网页的交互性和动态功能。
- WAI(Web Accessibility Initiative):旨在提高Web内容的可访问性,确保所有用户(包括残障人士)都能平等地使用网络。
- SEO(搜索引擎优化)标准:提高网页在搜索引擎结果中排名的标准和最佳实践。

而规定这些Web标准的组织主要有:
- W3C(World Wide Web Consortium):负责制定Web的核心标准,如HTML、CSS、XML等。
- WHATWG(Web Hypertext Application Technology Working Group):关注HTML和DOM等技术的标准化,推动HTML5的发展。
- IETF(Internet Engineering Task Force):负责制定互联网协议标准,如HTTP、SMTP等。
Web标准是构建现代Web应用和网站的基础,它们确保了不同平台之间的兼容性和一致性,促进了Web的可持续发展。遵循Web标准不仅可以提高用户体验,还能增强网站的可维护性和可访问性。
这里给各位小伙伴推荐一个快速学习和查看不同Web标准的网站:https://developer.mozilla.org/
Mozilla开发者网络提供的丰富文档,涵盖HTML、CSS、JavaScript等技术,包含教程和参考资料。
WebStorm安装和配置
前面我们给大家介绍了Web相关的预备知识点,现在我们就正式准备上手开发吧,这里我们需要先安装WebStorm作为集成开发环境(IDE)相比直接使用记事本来编写代码,IDE可以为我们提供更加完善的代码编写体验,比如语法错误检查,代码提示等,同时它还集成了一些常用的开发工具。
下载地址:WebStorm:JetBrains 出品的 JavaScript 和 TypeScript IDE

我们直接点击下载即可:

这个软件针对于个人来说免费使用的,各位小伙伴无需担心后续使用问题。
下载好之后,直接安装即可,这个不强制要求安装到C盘,自己随意,但是注意路径中不要出现中文。
这里勾选一下创建桌面快捷方式就行:
安装完成后,我们直接打开就可以了:
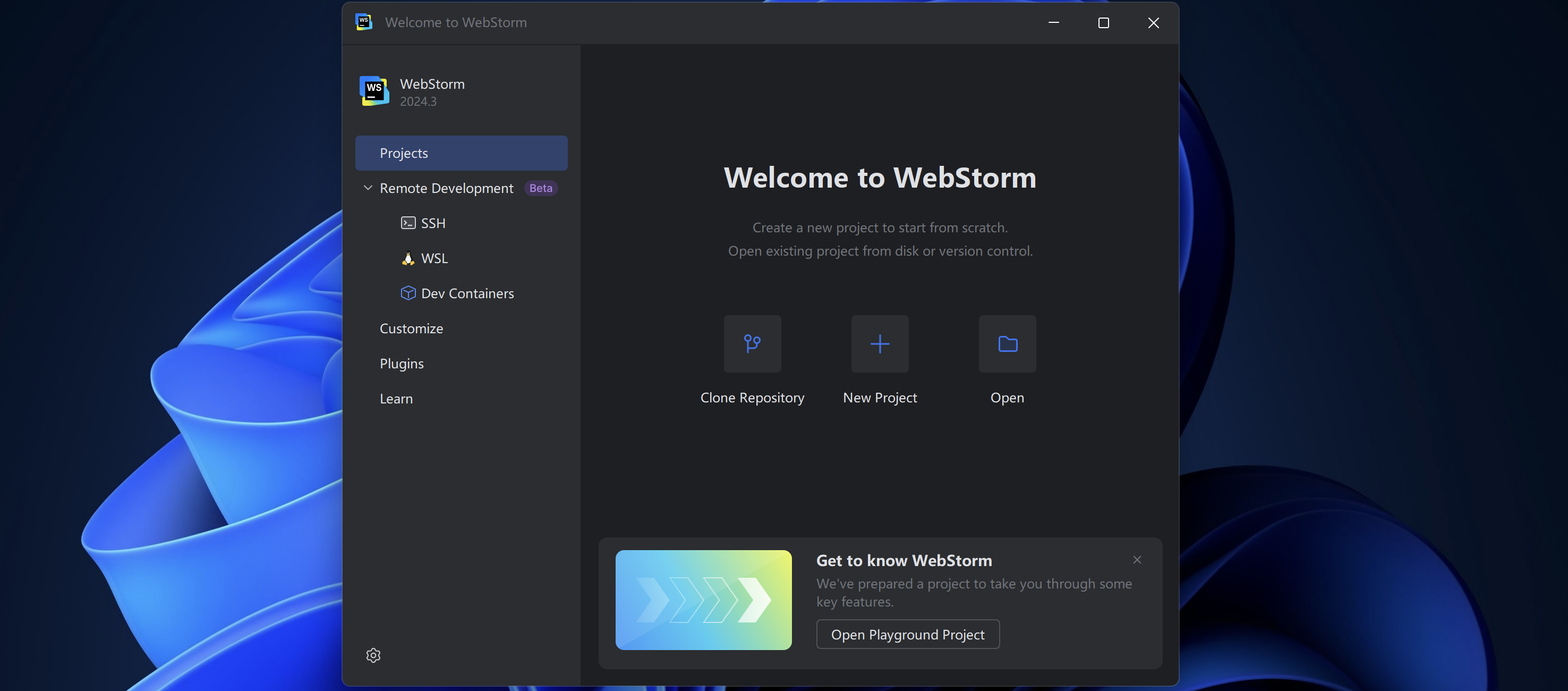
此时界面是全英文,如果各位小伙伴看得惯,可以直接使用全英文的界面(使用英文界面可以认识更多的专业术语词汇,但是可能看起来没中文那么直观,而且IDEA本身功能就比较多,英语不好的小伙伴就很头疼)这里还是建议使用中文界面,要使用中文只需在Customize里面配置语言即可:
如果各位小伙伴不喜欢黑色主题,也可以修改为白色主题,只需要在自定义中进行修改即可,一共四种主题。
接下来,我们来看看如何使用WebStorm创建一个新的Web项目,WebStorm是以项目的形式进行管理的,所以说我们直接创建一个新的项目即可,点击新建项目,然后选择空项目:
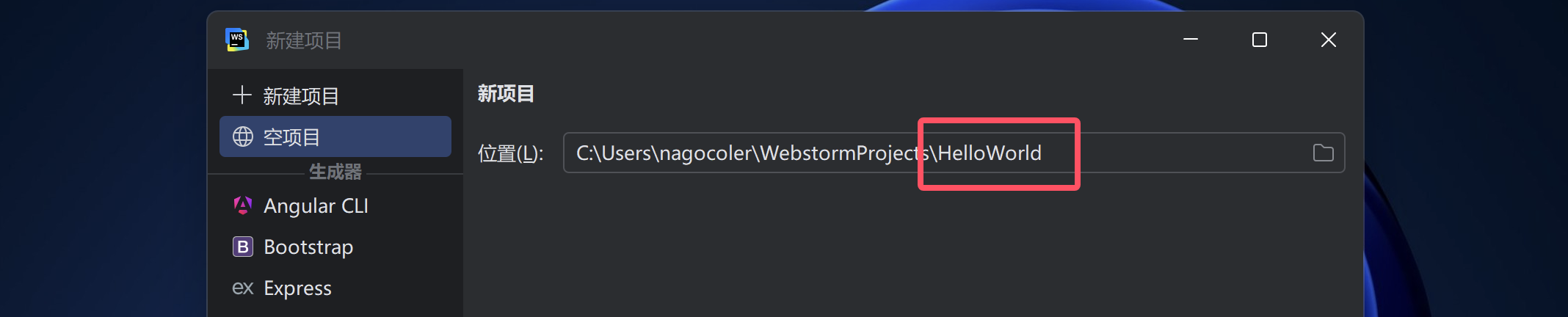
最后一级目录就是我们的项目名称,这里我们起名为HelloWorld即可,然后点击右下角的创建按钮。
进入之后,我们可以看到项目目录下没有任何文件(这里的.idea目录是WebStorm项目的相关设置,直接无视即可)
这里我们来尝试编写一个简单的页面看看能否正常加载,我们右键项目目录,然后选择新建一个HTML文件:
这里我们将其命名为index,此时项目目录下就会出现一个新的index.html文件:
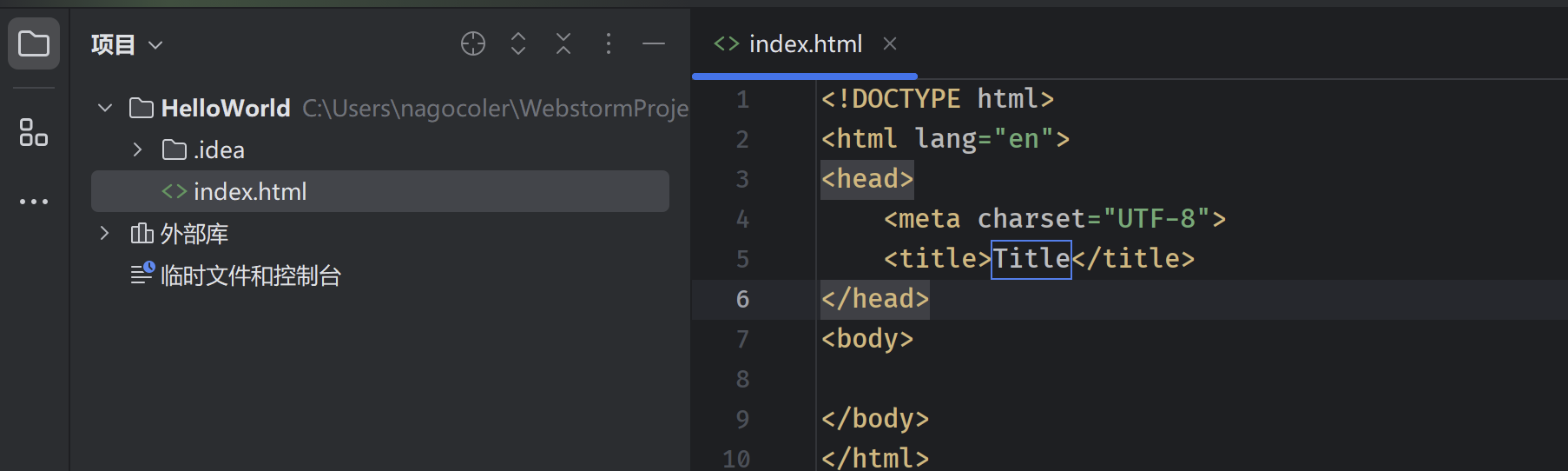
这是一个最基本的网页源代码文件,可以看到里面写了很多我们暂时还看不懂的代码,不过没关系,我们现在只是简单体验一下,并不需要各位小伙伴马上理解其中的含义。
这里我们尝试在body中编写一些测试的代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>Hello World</div>
</body>
</html>接着,我们可以在浏览器中查看我们编写的网页长什么样子,在WebStorm的右上角有一个选择栏,我们可以直接点击然后让对应的浏览器展示我们的页面:
这里我们以Chrome作为测试开发浏览器,打开后就是这样的:
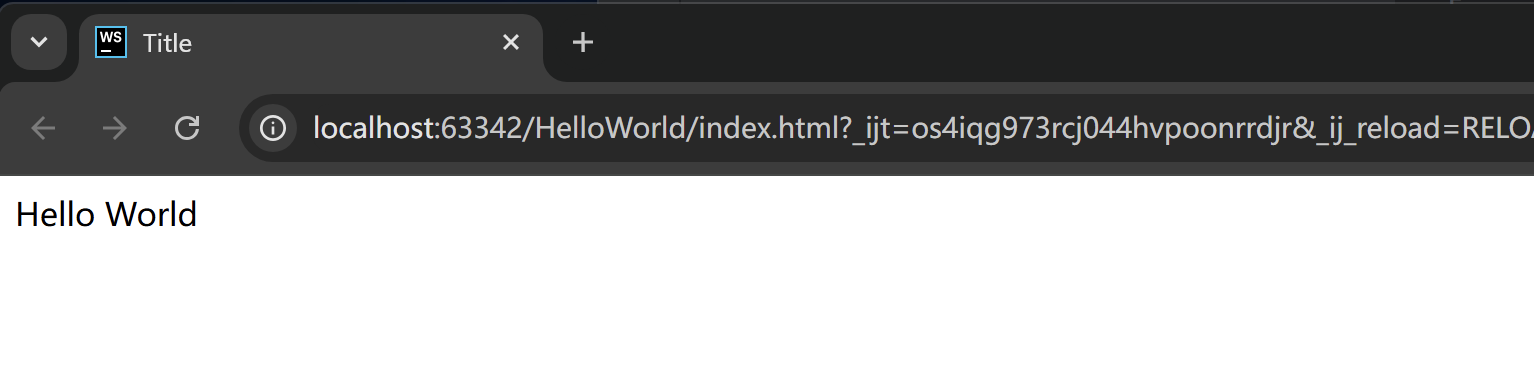
当各位小伙伴能看到页面中展示出了HelloWorld后,恭喜你们完成了自己第一个网页的开发。
HTML基础
前面我们带大家体验了创建一个HTML文件并在浏览器中访问,从这一节开始,我们就可以正式进入到HTML的学习了。
HTML(超文本标记语言,HyperText Markup Language)是一种用于创建网页和Web应用程序的标准标记语言(严格来说它并不是编程语言)它通过使用标记(Tags)来定义文档的结构和内容,通常与CSS(层叠样式表)和JavaScript一起使用,以实现网页的样式和交互功能。
实际上我们访问一个网页,就是访问的它对应的HTML文件,浏览器读取这个HTML文件的源代码即可解析为对应的网页展示在我们的面前。
HTML语法基础
HTML语言采用标签的形式进行编写,标签都是被包含在尖括号内,尖括号内可以填写一个标签的名字,它大概长这样:
<test>只不过,在HTML中,标签不一定是这种单个出现的情况,很多标签都是成对出现的,比如我们之后会经常用到的div标签,它必须要存在前后闭合:
<div></div>后面闭合的这个标签必须要添加/表示这是一个结束标签。像这种要求成对出现的标签我们一般称其为 **“双标签” **或是 “一般标签”,而允许单个出现的我们一般称其为 “单标签” 或是 “自闭合标签”。那么为什么会出现双标签和单标签之分呢?实际上双标签是支持嵌套编写内容的,就像这样:
<div>
<div></div>
</div>可以看到,标签之间是可以进行嵌套的,甚至可以无限嵌套下去,但是注意这种嵌套只能完整包含一个标签,不得出现交叉的情况。像这样将标签嵌套编写到另一个标签中,我们称其为子标签或是子节点,而囊括它的标签我们称其为父标签或是父节点,同样的,如果是与其相邻的按顺序编写的标签,我们称其为兄弟标签或兄弟节点:
<div></div>
<div></div>
<br>然后需要注意的是,HTML的标签名称已经为我们提前预设好了,不同的HTML标签会被浏览器解析成不同的样式或是组件,我们自己随便编写的标签名称在被浏览器解析时实际上是没有意义的,从下节课开始我们就会带大家依次认识不同的浏览器标签以及其作用。
有些标签还可以单独配置一些额外的属性,标签属性一般用于控制标签的一些行为或是效果,属性一般像这样编写:
<img src="test.png" alt="白丝写真照">注意属性需要在标签的内部编写属性名称="值"的形式,同时属性的值必须是囊括在双引号内,并且不能跟标签名称写在一起,当出现多个不同属性时,还是需要使用空格隔开(空格数量可以是1个或多个)
我们接着来看看一个基本的 HTML 文档结构,我们上一节带大家创建的HTML文件默认长这样:
<!DOCTYPE html>
<html lang="zh">
<head>
</head>
<body>
</body>
</html>- 首先是最上面的
<!DOCTYPE html>用于声明文档类型,它是一种特殊的标签,唯一作用就是告诉浏览器使用HTML标准解析该文档。 - 接着是
<html>标签,它是HTML文档的根元素,包含整个网页文档的内容,可以看到它是一个双标签,囊括了head和body标签在内,这里有一个lang属性用于指示网页使用的语言(仅对浏览器有指示作用) head标签表示页头中的内容,是网页的“头部”,用于定义网页的基本信息或是一些特殊内容,比如页面的标题、介绍、特殊信息等,我们一般不会在这里编写网页中需要展示的内容(即使在这里编写也会被浏览器强制移动到body标签中)body就是网页的身体,也叫页身,几乎所有页面中需要展示的内容都在这里编写,我们在开发网页时主要编写的也是页身这一部分。
我们先来看看页头中有哪些常见的标签:
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>首先是title标签,它一般编写在head标签中,作为页头的一部分,它用于声明我们网页的标题,网页的标题会在浏览器的顶部展示:

我们可以修改这个标签里面囊括的内容,来实现修改标题:
<title>你干嘛哎哟</title>
是不是感觉很简单?只要我们按照对应标签的作用去使用它们,就能很轻松地实现我们想要的效果,而HTML的学习也主要是认识标签和各种标签属性,以及它们的使用场景。
我们接着来看meta属性,它一般用于定义页面的特殊信息,如页面的关键字,页面的描述以及一些针对于搜索引擎的属性等。这些信息主要面向的不是用户,更多的是搜索引擎。比如我们在百度搜索某个网站时,会展示出此网站的一些介绍信息:
而这些介绍信息以及网页的一些其他设置,我们都可以在meta标签中进行编辑,比如这里的:
<meta charset="UTF-8">表示我们的网页使用的是UTF-8编码格式(现在网站一般都统一使用UTF-8格式编码)浏览器会按照对应的编码格式进行解析,防止某些浏览器出现文字乱码。
此外,meta标签还可以编写多种不同的属性,比如我们官网的:
<meta name="keywords" content="柏码,白马程序员,itbaima,白马,青空の霞光,青空的霞光,柏码官网,白马程序员官网">
<meta name="description" property="og:title" content="专注于计算机系列知识分享,为广大编程爱好者提供良好的学习环境,所有基础学习资源全部免费开放">有关meta标签的标准元属性名称,可以在:https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/meta/name 中进行详细阅读。此标签新手阶段仅做了解即可,无需深入学习。
当然,head内部不仅仅只能使用title和meta两种标签,还有style、link、script等标签会在后续的CSS和JavaScript课程中为大家介绍。
我们接着来看body标签,它代表我们网页的页身,我们上一节在页身中编写了一些测试的代码,一个很简单的标签:
<div>Hello World</div>这实际上是一个盒子标签,我们会在后面的课程中对其进行详细介绍。在页身编写的内容则会被浏览器作为内容渲染到页面中展示:
至此,有关一个HTML文档最基本的格式就暂时先介绍到这里,从下一节开始,我们将逐步认识HTML中那些丰富多彩的标签。
文本相关标签
前面我们介绍了网页的最基本结构,那么从这一节开始,我们就先从文本相关的标签开始学习。
首先,如果我们直接在body中编写一段文本,那么此文本会直接被浏览器渲染:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>你干嘛哎哟</title>
</head>
<body>
啊真的是你鸭
</body>
</html>但是如果仅仅只是渲染一段文本,是没办法构建出一个精美的网页的,我们可以发现很多的文档网站里面,标签和内容的大小以及字体样式是不一致的:

如果我们只是简单的在HTML中编写这样的排版:
<body>
我是标题
我是这个文档的内容,我要成为最强的全干开发工程师
</body>此时浏览器中渲染出来的内容并不是我们所期望的那样:

这是因为在HTML中,无论我们如何使用空格或是换行,最终都只会识别成一个单独的空格。因此,如果我们想对页面中的文字内容进行排版,直接编写是不行的,
HTML为我们提供了一些更具语义化的标签,来实现页面中不同文本信息的展示样式。首先我们来介绍一下标题,标题是一篇文章的开头,HTML为我们提供了6个等级的标题可以使用,分别是h1到h6共6个标签,大小依次递减。
比如现在我们想创建一个一级标题,也就是最大的标题:
<body>
<h1>我是一个简单的标题</h1>
我是一个简单的内容,专门衬托标题用的,如果觉得我没用就删了我吧
</body>此时,浏览器就会为我们渲染成这样:

可以看到,浏览器在遇到h1标签时,自动将其解析为了一个一级标题,无论是字体的大小还是粗细,都与普通的文本存在差别。这样我们就可以做一个简单的文档排版了。
在HTML中,标签和普通文本是可以交错存在的。
这里我们把6个等级的标题都列出来给各位小伙伴一个参考:
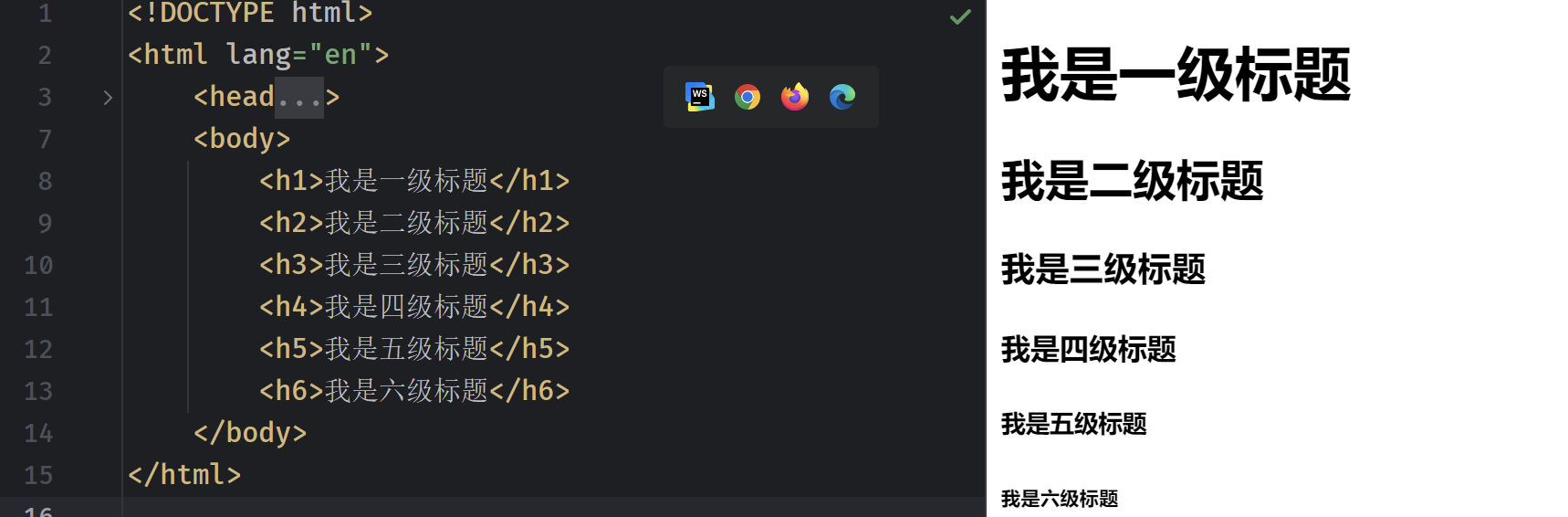
按照一篇正常的文档来说,一般只会存在一个一级标题,然后就是一系列二级标题和更次级的标题,具体情况可以参考官网的知识库文档。
HTML中不同的标签有着不同的语义,尽可能地使用正确的语义化标签,还可以优化搜索引擎对网页的处理。
接着我们来看段落标签,现在有了标题,我们的文章可以按照章节进行划分了,但是,一个章节内的文本,肯定还会被分成多个段落展示,就像我们写作文一样需要分多少个自然段。这时就需要用到段落标签p了,同样是将文本囊括在内:
<p>自2024年11月20日06:00起:停止原神小米服务器的游戏充值和新用户注册功能</p>
<p>自2025年01月20日12:00起:正式关停原神在小米平台的运营,关闭游戏在小米平台的下载入口及关闭游戏服务器</p>此时,每一个p标签都表示为一个段落,在多个段落之间会自动换行,并且会出现明显的段距:

除了使用p标签来进行段落划分外,HTML还提供了一个hr标签来使用水平线划分段落:
自2024年11月20日06:00起:停止原神小米服务器的游戏充值和新用户注册功能
<hr>
自2025年01月20日12:00起:正式关停原神在小米平台的运营,关闭游戏在小米平台的下载入口及关闭游戏服务器
现在我们就可以对文档进行标题和分段的划分了,只不过,光是这样还不够,有些时候我们可能希望为文字添加各种不同的字体样式或是修饰,我们接着来看一下对文本进行修饰的标签。
首先是粗体标签,这对于一些重点的信息突出非常重要,我们可以使用b或是strong来实现:
据CNMO了解,小米汽车在车展现场派发的<b>矿泉水</b>,竟然被人挂到了二手平台闲鱼上,最高<b>卖到99.99元</b>,网友看完后直呼“逆天”。此时,被b标签包裹的元素,被浏览器加粗渲染了:

既然有粗体,那么肯定还有斜体,我们可以使用i,em,cite:
武汉一位40岁男子与10岁小孩因口角,<em>气愤之下连划7辆车进行报复</em>,声称“总有一辆是小孩家的”。
有些时候,我们可能还需要用到上下标来表示一些特殊数据,比如某个数字的平方,此时我们可以使用sup来表示上标,使用sub来表示下标:
广州一女子,入职仅<sup>58</sup>天却<sup>21</sup>次迟到,且工作能力与简历不符,被公司辞退。
女子不满公司补偿,申请劳动仲裁。结果劳动仲裁开庭当天,她迟到了<sub>16</sub>分钟。
仲裁结果支持了公司,驳回了她的申请。
有些时候,我们可能希望使用下划线来标注某些重要的文本或是使用中划线删除某些不重要的文本,此时我们可以使用s和u标签来实现中划线和下划线效果:
一男子因声称要<s>炸火车站</s>被拘留,民警询问哪个火车站,此男子回答道是北京火车站,
接着民警提醒他这里是上海,然后男子便说<u>那为什么要把我抓进来呢?</u>
当然还有单独控制字体大小的标签,比如small和big可以简单控制文本大小,这里就不演示了。可能会有很多小伙伴疑惑,那文本的颜色该怎么设置呢?我们前面说到HTML本身只是网页的骨架,而样式的修改需要结合后面学习的CSS才能实现,包括这里的文本样式在不使用以上修饰标签的情况下也可以通过CSS来调整,我们会在后续课程中逐步介绍。
除此之外,如果我们单纯想对文本进行换行,也可以直接使用br标签,这是一个单标签,可以直接嵌入到我们想要换行的位置上去:
我是第一行<br>我是第二行
有关文本相关的标签,我们就暂时先介绍到这里。
注释和特殊符号
在实际开发中,我们可能需要在一些HTML代码旁边注明这段代码是干什么的,防止自己下次阅读代码时忘记这里的意义,这个时候我们就可以使用注释来完成。
注释仅仅是对代码的批注,不属于代码的一部分,也不会被浏览器解析,仅针对于我们开发者使用,要声明一个注释需要使用以下格式:
<!-- 我是内容 -->开头需要使用一个尖括号加感叹号外加至少两个减号,结尾也需要一个尖括号来收尾,注释内容可以在其内部自由编写。
在HTML源代码中,注释可以随意穿插在任何位置且不影响其他正常的内容:
自2024年11月20日06:00起:<!-- 我是内容 -->停止原神小米服务器的<br>游戏充值和新用户注册功能在浏览器中这段注释会自动被忽略:

为项目中的代码编写注释是一个非常好的习惯,因为随着我们项目开发越来越庞大,很多模块都会逐步被遗忘,回头再来查阅某些代码或是其他小伙伴来阅读我们的代码时,没有注释就会变得难以理解,要花费更多的时间去重新阅读代码。
前面我们在学习文本相关标签时,就遇到一个问题,我们无论在HTML代码中怎么换行还是空格,最终都会被浏览器解析为一个单独的空格,虽然可以通过一些语义化标签进行排版,但是有些时候可能我们就是希望直接展示为多个空格或是一些其他的字符,那这个时候该怎么办呢?
实际上这些字符在HTML中都属于特殊符号,我们就可以使用特殊符号对应的代码来表示,比如空格的代码是nbsp,那么想要在HTML表示空格就可以像这样:
你好 空格够了不使用特殊符号需要以&开头并以;结尾,我们一般称其为字符实体或是转义字符,通过使用这些特殊符号代码,指定的字符就可以出现在我们的页面中了。
当然,除了空格外,实际上还有一些字符也是特殊符号,其中最常见的就是大于和小于符号,因为它们被用作HTML标签的囊括符号使用,因此,如果我们随意地使用大于小于符号,某些情况下会出现问题:
<p>都什么年代了,还在抽<传统香烟></p>这里文本中的大于小于符号实际上只是我们单纯想表示出来的一个字符,但是由于HTML语法原因,它被解析成了一个单标签,这显然是不正确的。此时我们就可以使用其对应的特殊字符代码来表示:
<p>都什么年代了,还在抽<传统香烟></p>这样就不会出现刚才的歧义了。
最后这里给大家列举一下常用的一些特殊符号代码:
| 特殊符号 | 名称 | 代码 |
|---|---|---|
| " | 英文双引号 | quot |
| _ | 空格 | nbsp |
| > | 大于 | gt |
| < | 小于 | lt |
| & | 与 | amp |
有关全部的特殊符号代码,可以参阅:https://developer.mozilla.org/zh-CN/docs/Glossary/Entity
行内元素和块级元素
在HTML中,标签也可以统称为**“元素”,而元素通常分为两种类型:行内元素(Inline Elements)和块级元素**(Block Elements)不同类型的元素直接决定了其占据页面的大小和布局,这是HTML中非常重要的概念。
我们在前面的学习中不难发现,某些元素会直接占据一整行宽度,而某些元素可以和文本穿插使用,与文本位于同一行中,比如h1标签作为标题,会直接独占一行,之后的文本自动被挤到下一行展示,再比如b标签,里面囊括的元素会自动加粗但并不会使其独占一行,而是正常与其他文本内容在同一行展示。
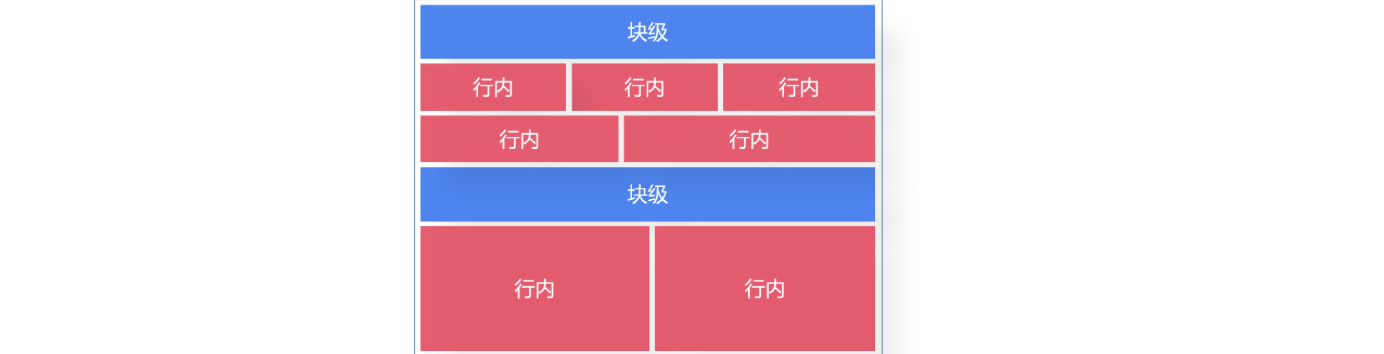
在我们之前认识的标签中,p、hr、h1~h6等,都是块级元素,它们会独占一行空间并排斥与其位于同一行的所有内容,比如:
十七张牌<p>你能秒我</p>我当场就吧这个电脑屏幕吃掉
可以看到,无论是在p元素前的内容还是在其之后的内容,都被挤开了,块级元素会独占这一行。
我们接着来看行内元素,它与块级元素恰恰相反,它可以和任何其他行内元素在同一行展示,我们之前认识的b、i、sup、sub、u、s等以及我们直接编写的不被任何标签囊括的普通文本节点,都属于行内元素:
<i>十七张牌<b>你能秒我</b>我当场<u>就吧这个</u>电脑屏幕吃掉</i>
可以看到,行内元素以及其内部包含的行内元素,最终渲染到浏览器上时都是位于同一行中。同时,结合之前的知识,实际上行内元素之间无论在源代码中如何空格或是换行,最终都会变成单个空格。
注意: 大多数(并非所有)行内元素只能包含行内元素,不可包含块级元素。但是与行内元素不同的是,大多数块级元素(同样并非所有)则既可以包含行内元素也可以包含块级元素,当一个块级元素包含其他块级元素时,在这个块的内部依然会按行进行划分,而行内元素则依然在同一行展示:
<p>
我是行内元素文本
<b>我是普通行内元素文本</b>
<h5>我是一个讨厌的块级元素</h5>
<h5>我是一个讨厌的块级元素</h5>
</p>
当然,这里只是一个简单的例子,虽然p标签确实是一个块级元素,但是根据其语义,它表示一个文本段落,HTML规定它的里面不应该包含其他块级元素,只是浏览器包容性比较强,可以正常显示罢了。因此,虽然大部分块级元素允许包含块级元素,但是我们还是需要按照不同的标签的具体规范来使用嵌套关系,行内元素也是同理,并不是说所有的都不允许内嵌块级元素。
我们接着来认识两个非常常用但是又没有什么实际意义的标签div和span,它们一般用于结构化和样式化网页内容。首先是div标签,全名为division分区,顾名思义就是拿来划分一个区域使用,他同样是一个块级元素,可以包含多种元素在内。但是div标签本本身并不具备任何语义,不像p标签表示段落、h1表示标题,它单纯就是拿来对文档结构进行划分或是分组的:
<div>
我是第一组行内元素文本
<b>我是普通行内元素文本</b>
<h5>我是一个讨厌的块级元素</h5>
<h5>我是一个讨厌的块级元素</h5>
</div>
<div>
我是第二组行内元素文本
<b>我是普通行内元素文本</b>
<h5>我是一个讨厌的块级元素</h5>
<h5>我是一个讨厌的块级元素</h5>
</div>
可以看到,效果确实和一个普通的块级元素一样,但是它和之前认识的p和h1标签不同,它不会自带间距,在遇到两个简单div标签并列时,看起来就像是单纯换了个行那样:
<div>我是第一组行内元素文本</div>
<div>我是第二组行内元素文本</div>可见,div标签给了我们最纯粹最简单的块级划分,我们可以利用这种特性来对代码中的一些模块进行分类,包括后续学习CSS的时候,还可以针对某个区域来单独设置样式,div标签也是我们非常常用的一个标签,由于它可以作为一个简单的容器,所以我们一般也可以把一个div标签叫做 “盒子”
接着就是span标签,和div一样,它是一个非常纯粹的行内元素,我们可以使用它来对行内模块进行划分:
<div>
<span>我是需要特殊处理的行内1</span>
<span>我是需要特殊处理的行内2</span>
<span>
<b>我是需要特殊处理的行内3</b>
</span>
</div>
当然,行内元素和块级元素的区别还不止这些,我们会在CSS阶段再来介绍更多的特性。