
NIO基础
注意: 推荐完成JavaSE篇、JavaWeb篇的学习再开启这一部分的学习,如果在这之前完成了JVM篇,那么看起来就会比较轻松了。
在JavaSE的学习中,我们了解了如何使用IO进行数据传输,Java IO是阻塞的,如果在一次读写数据调用时数据还没有准备好,或者目前不可写,那么读写操作就会被阻塞直到数据准备好或目标可写为止。Java NIO则是非阻塞的,每一次数据读写调用都会立即返回,并将目前可读(或可写)的内容写入缓冲区或者从缓冲区中输出,即使当前没有可用数据,调用仍然会立即返回并且不对缓冲区做任何操作。
NIO框架是在JDK1.4推出的,它的出现就是为了解决传统IO的不足,这一期视频,我们就将围绕着NIO开始讲解。
缓冲区
一切的一切还要从缓冲区开始讲起,包括源码在内,其实这个不是很难,只是需要理清思路。
Buffer类及其实现
Buffer类是缓冲区的实现,类似于Java中的数组,也是用于存放和获取数据的。但是Buffer相比Java中的数组,功能就非常强大了,它包含一系列对于数组的快捷操作。
Buffer是一个抽象类,它的核心内容:
public abstract class Buffer {
// 这四个变量的关系: mark <= position <= limit <= capacity
// 这些变量就是Buffer操作的核心了,之后我们学习的过程中可以看源码是如何操作这些变量的
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
// 直接缓冲区实现子类的数据内存地址(之后会讲解)
long address;我们来看看Buffer类的子类,包括我们认识到的所有基本类型(除了boolean类型之外):
- IntBuffer - int类型的缓冲区。
- ShortBuffer - short类型的缓冲区。
- LongBuffer - long类型的缓冲区。
- FloatBuffer - float类型的缓冲区。
- DoubleBuffer - double类型的缓冲区。
- ByteBuffer - byte类型的缓冲区。
- CharBuffer - char类型的缓冲区。
(注意我们之前在JavaSE中学习过的StringBuffer虽然也是这种命名方式,但是不属于Buffer体系,这里不会进行介绍)
这里我们以IntBuffer为例,我们来看看如何创建一个Buffer类:
public static void main(String[] args) {
//创建一个缓冲区不能直接new,而是需要使用静态方法去生成,有两种方式:
//1. 申请一个容量为10的int缓冲区
IntBuffer buffer = IntBuffer.allocate(10);
//2. 可以将现有的数组直接转换为缓冲区(包括数组中的数据)
int[] arr = new int[]{1, 2, 3, 4, 5, 6};
IntBuffer buffer = IntBuffer.wrap(arr);
}那么它的内部是本质上如何进行操作的呢?我们来看看它的源码:
public static IntBuffer allocate(int capacity) {
if (capacity < 0) //如果申请的容量小于0,那还有啥意思
throw new IllegalArgumentException();
return new HeapIntBuffer(capacity, capacity); //可以看到这里会直接创建一个新的IntBuffer实现类
//HeapIntBuffer是在堆内存中存放数据,本质上就数组,一会我们可以在深入看一下
}public static IntBuffer wrap(int[] array, int offset, int length) {
try {
//可以看到这个也是创建了一个新的HeapIntBuffer对象,并且给了初始数组以及截取的起始位置和长度
return new HeapIntBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
public static IntBuffer wrap(int[] array) {
return wrap(array, 0, array.length); //调用的是上面的wrap方法
}那么这个HeapIntBuffer又是如何实现的呢,我们接着来看:
HeapIntBuffer(int[] buf, int off, int len) { // 注意这个构造方法不是public,是默认的访问权限
super(-1, off, off + len, buf.length, buf, 0); //你会发现这怎么又去调父类的构造方法了,绕来绕去
//mark是标记,off是当前起始下标位置,off+len是最大下标位置,buf.length是底层维护的数组真正长度,buf就是数组,最后一个0是起始偏移位置
}我们又来看看IntBuffer中的构造方法是如何定义的:
final int[] hb; // 只有在堆缓冲区实现时才会使用
final int offset;
boolean isReadOnly; // 只有在堆缓冲区实现时才会使用
IntBuffer(int mark, int pos, int lim, int cap, // 注意这个构造方法不是public,是默认的访问权限
int[] hb, int offset)
{
super(mark, pos, lim, cap); //调用Buffer类的构造方法
this.hb = hb; //hb就是真正我们要存放数据的数组,堆缓冲区底层其实就是这么一个数组
this.offset = offset; //起始偏移位置
}最后我们来看看Buffer中的构造方法:
Buffer(int mark, int pos, int lim, int cap) { // 注意这个构造方法不是public,是默认的访问权限
if (cap < 0) //容量不能小于0,小于0还玩个锤子
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap; //设定缓冲区容量
limit(lim); //设定最大position位置
position(pos); //设定起始位置
if (mark >= 0) { //如果起始标记大于等于0
if (mark > pos) //并且标记位置大于起始位置,那么就抛异常(至于为啥不能大于我们后面再说)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark; //否则设定mark位置(mark默认为-1)
}
}通过对源码的观察,我们大致可以得到以下结构了:

现在我们来总结一下上面这些结构的各自职责划分:
- Buffer:缓冲区的一些基本变量定义,比如当前的位置(position)、容量 (capacity)、最大限制 (limit)、标记 (mark)等,你肯定会疑惑这些变量有啥用,别着急,这些变量会在后面的操作中用到,我们逐步讲解。
- IntBuffer等子类:定义了存放数据的数组(只有堆缓冲区实现子类才会用到)、是否只读等,也就是说数据的存放位置、以及对于底层数组的相关操作都在这里已经定义好了,并且已经实现了Comparable接口。
- HeapIntBuffer堆缓冲区实现子类:数据存放在堆中,实际上就是用的父类的数组在保存数据,并且将父类定义的所有底层操作全部实现了。
这样,我们对于Buffer类的基本结构就有了一个大致的认识。
缓冲区写操作
前面我们了解了Buffer类的基本操作,现在我们来看一下如何向缓冲区中存放数据以及获取数据,数据的存放包括以下四个方法:
- public abstract IntBuffer put(int i); - 在当前position位置插入数据,由具体子类实现
- public abstract IntBuffer put(int index, int i); - 在指定位置存放数据,也是由具体子类实现
- public final IntBuffer put(int[] src); - 直接存放所有数组中的内容(数组长度不能超出缓冲区大小)
- public IntBuffer put(int[] src, int offset, int length); - 直接存放数组中的内容,同上,但是可以指定存放一段范围
- public IntBuffer put(IntBuffer src); - 直接存放另一个缓冲区中的内容
我们从最简的开始看,是在当前位置插入一个数据,那么这个当前位置是怎么定义的呢,我们来看看源码:
public IntBuffer put(int x) {
hb[ix(nextPutIndex())] = x; //这个ix和nextPutIndex()很灵性,我们来看看具体实现
return this;
}
protected int ix(int i) {
return i + offset; //将i的值加上我们之前设定的offset偏移量值,但是默认是0(非0的情况后面会介绍)
}
final int nextPutIndex() {
int p = position; //获取Buffer类中的position位置(一开始也是0)
if (p >= limit) //位置肯定不能超过底层数组最大长度,否则越界
throw new BufferOverflowException();
position = p + 1; //获取之后会使得Buffer类中的position+1
return p; //返回当前的位置
}所以put操作实际上是将底层数组hb在position位置上的数据进行设定。

设定完成后,position自动后移:

我们可以编写代码来看看:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.allocate(10);
buffer
.put(1)
.put(2)
.put(3); //我们依次存放三个数据试试看
System.out.println(buffer);
}通过断点调试,我们来看看实际的操作情况:
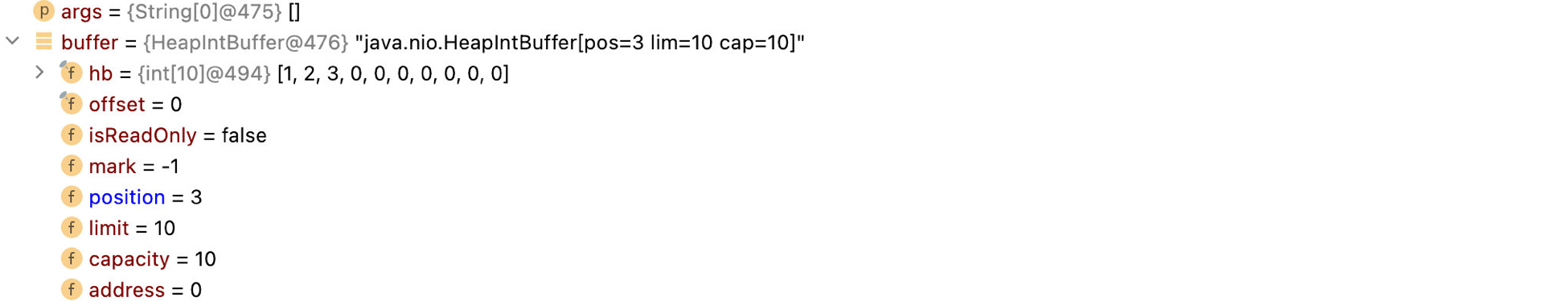
可以看到我们不断地put操作,position会一直向后移动,当然如果超出最大长度,那么会直接抛出异常:

接着我们来看看第二个put操作是如何进行,它能够在指定位置插入数据:
public IntBuffer put(int i, int x) {
hb[ix(checkIndex(i))] = x; //这里依然会使用ix,但是会检查位置是否合法
return this;
}
final int checkIndex(int i) { // package-private
if ((i < 0) || (i >= limit)) //插入的位置不能小于0并且不能大于等于底层数组最大长度
throw new IndexOutOfBoundsException();
return i; //没有问题就把i返回
}实际上这个比我们之前的要好理解一些,注意全程不会操作position的值,这里需要注意一下。
我们接着来看第三个put操作,它是直接在IntBuffer中实现的,是基于前两个put方法的子类实现来完成的:
public IntBuffer put(int[] src, int offset, int length) {
checkBounds(offset, length, src.length); //检查截取范围是否合法,给offset、调用者指定长度、数组实际长度
if (length > remaining()) //接着判断要插入的数据量在缓冲区是否容得下,装不下也不行
throw new BufferOverflowException();
int end = offset + length; //计算出最终读取位置,下面开始for
for (int i = offset; i < end; i++)
this.put(src[i]); //注意是直接从postion位置开始插入,直到指定范围结束
return this; //ojbk
}
public final IntBuffer put(int[] src) {
return put(src, 0, src.length); //因为不需要指定范围,所以直接0和length,然后调上面的,多捞哦
}
public final int remaining() { //计算并获取当前缓冲区的剩余空间
int rem = limit - position; //最大容量减去当前位置,就是剩余空间
return rem > 0 ? rem : 0; //没容量就返回0
}static void checkBounds(int off, int len, int size) { // package-private
if ((off | len | (off + len) | (size - (off + len))) < 0) //让我猜猜,看不懂了是吧
throw new IndexOutOfBoundsException();
//实际上就是看给定的数组能不能截取出指定的这段数据,如果都不够了那肯定不行啊
}大致流程如下,首先来了一个数组要取一段数据全部丢进缓冲区:
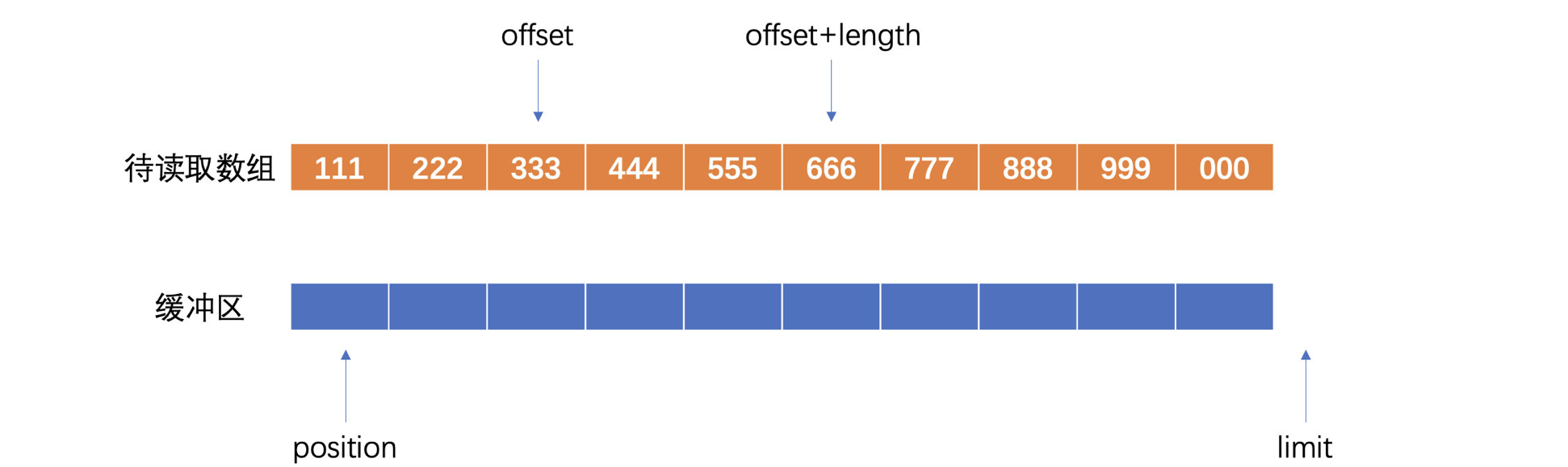
在检查没有什么问题并且缓冲区有容量时,就可以开始插入了:
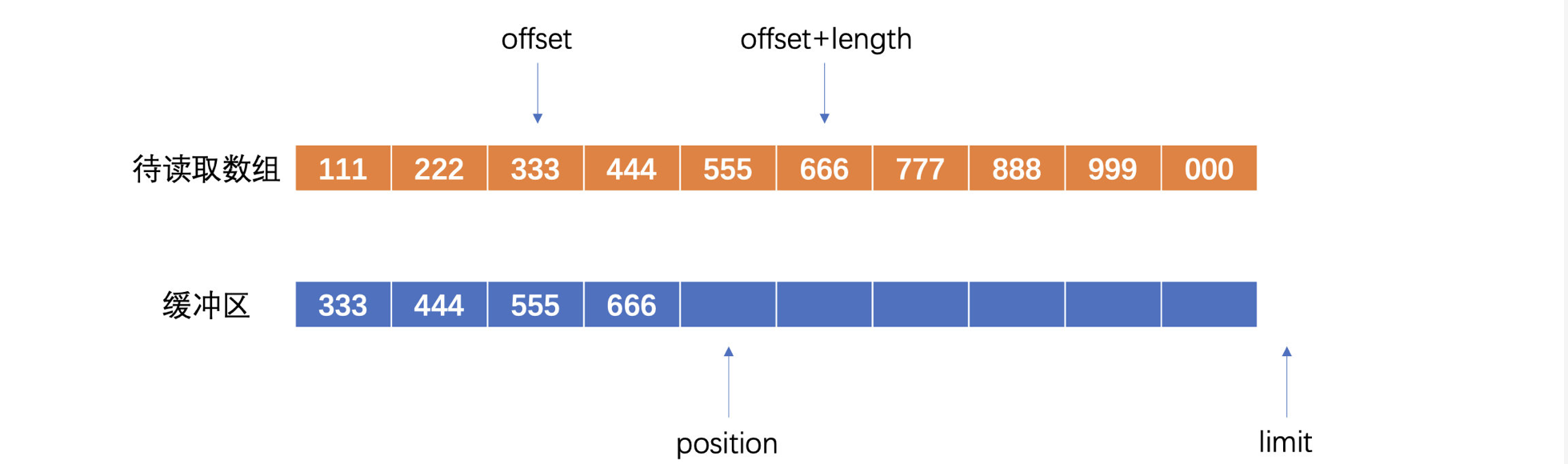
最后我们通过代码来看看:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.allocate(10);
int[] arr = new int[]{1,2,3,4,5,6,7,8,9};
buffer.put(arr, 3, 4); //从下标3开始,截取4个元素
System.out.println(Arrays.toString(buffer.array())); //array方法可以直接获取到数组
}可以看到最后结果为:

当然我们也可以将一个缓冲区的内容保存到另一个缓冲区:
public IntBuffer put(IntBuffer src) {
if (src == this) //不会吧不会吧,不会有人保存自己吧
throw new IllegalArgumentException();
if (isReadOnly()) //如果是只读的话,那么也是不允许插入操作的(我猜你们肯定会问为啥就这里会判断只读,前面四个呢)
throw new ReadOnlyBufferException();
int n = src.remaining(); //给进来的src看看容量(注意这里不remaining的结果不是剩余容量,是转换后的,之后会说)
if (n > remaining()) //这里判断当前剩余容量是否小于src容量
throw new BufferOverflowException();
for (int i = 0; i < n; i++) //也是从position位置开始继续写入
put(src.get()); //通过get方法一个一个读取数据出来,具体过程后面讲解
return this;
}我们来看看效果:
public static void main(String[] args) {
IntBuffer src = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
IntBuffer buffer = IntBuffer.allocate(10);
buffer.put(src);
System.out.println(Arrays.toString(buffer.array()));
}但是如果是这样的话,会出现问题:
public static void main(String[] args) {
IntBuffer src = IntBuffer.allocate(5);
for (int i = 0; i < 5; i++) src.put(i); //手动插入数据
IntBuffer buffer = IntBuffer.allocate(10);
buffer.put(src);
System.out.println(Arrays.toString(buffer.array()));
}我们发现,结果和上面的不一样,并没有成功地将数据填到下面的IntBuffer中,这是为什么呢?实际上就是因为remaining()的计算问题,因为这个方法是直接计算postion的位置,但是由于我们在写操作完成之后,position跑到后面去了,也就导致remaining()结果最后算出来为0。
因为这里不是写操作,是接下来需要从头开始进行读操作,所以我们得想个办法把position给退回到一开始的位置,这样才可以从头开始读取,那么怎么做呢?一般我们在写入完成后需要进行读操作时(后面都是这样,不只是这里),会使用flip()方法进行翻转:
public final Buffer flip() {
limit = position; //修改limit值,当前写到哪里,下次读的最终位置就是这里,limit的作用开始慢慢体现了
position = 0; //position归零
mark = -1; //标记还原为-1,但是现在我们还没用到
return this;
}这样,再次计算remaining()的结果就是我们需要读取的数量了,这也是为什么put方法中要用remaining()来计算的原因,我们再来测试一下:
public static void main(String[] args) {
IntBuffer src = IntBuffer.allocate(5);
for (int i = 0; i < 5; i++) src.put(i);
IntBuffer buffer = IntBuffer.allocate(10);
src.flip(); //我们可以通过flip来翻转缓冲区
buffer.put(src);
System.out.println(Arrays.toString(buffer.array()));
}翻转之后再次进行转移,就正常了。
缓冲区读操作
前面我们看完了写操作,现在我们接着来看看读操作。读操作有四个方法:
public abstract int get();- 直接获取当前position位置的数据,由子类实现public abstract int get(int index);- 获取指定位置的数据,也是子类实现public IntBuffer get(int[] dst)- 将数据读取到给定的数组中public IntBuffer get(int[] dst, int offset, int length)- 同上,加了个范围
我们还是从最简单的开始看,第一个get方法的实现在IntBuffer类中:
public int get() {
return hb[ix(nextGetIndex())]; //直接从数组中取就完事
}
final int nextGetIndex() { // 好家伙,这不跟前面那个一模一样吗
int p = position;
if (p >= limit)
throw new BufferUnderflowException();
position = p + 1;
return p;
}可以看到每次读取操作之后,也会将postion+1,直到最后一个位置,如果还要继续读,那么就直接抛出异常。

我们来看看第二个:
public int get(int i) {
return hb[ix(checkIndex(i))]; //这里依然是使用checkIndex来检查位置是否非法
}我们来看看第三个和第四个:
public IntBuffer get(int[] dst, int offset, int length) {
checkBounds(offset, length, dst.length); //跟put操作一样,也是需要检查是否越界
if (length > remaining()) //如果读取的长度比可以读的长度大,那肯定是不行的
throw new BufferUnderflowException();
int end = offset + length; //计算出最终读取位置
for (int i = offset; i < end; i++)
dst[i] = get(); //开始从position把数据读到数组中,注意是在数组的offset位置开始
return this;
}
public IntBuffer get(int[] dst) {
return get(dst, 0, dst.length); //不指定范围的话,那就直接用上面的
}我们来看看效果:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
int[] arr = new int[10];
buffer.get(arr, 2, 5);
System.out.println(Arrays.toString(arr));
}
可以看到成功地将数据读取到了数组中。
当然如果我们需要直接获取数组,也可以使用array()方法来拿到:
public final int[] array() {
if (hb == null) //为空那说明底层不是数组实现的,肯定就没法转换了
throw new UnsupportedOperationException();
if (isReadOnly) //只读也是不让直接取出的,因为一旦取出去岂不是就能被修改了
throw new ReadOnlyBufferException();
return hb; //直接返回hb
}我们来试试看:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
System.out.println(Arrays.toString(buffer.array()));
}当然,既然都已经拿到了底层的hb了,我们来看看如果直接修改之后是不是读取到的就是我们的修改之后的结果了:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
int[] arr = buffer.array();
arr[0] = 99999; //拿到数组对象直接改
System.out.println(buffer.get());
}可以看到这种方式由于是直接拿到的底层数组,所有修改会直接生效在缓冲区中。
当然除了常规的读取方式之外,我们也可以通过mark()来实现跳转读取,这里需要介绍一下几个操作:
public final Buffer mark()- 标记当前位置public final Buffer reset()- 让当前的position位置跳转到mark当时标记的位置
我们首先来看标记方法:
public final Buffer mark() {
mark = position; //直接标记到当前位置,mark变量终于派上用场了,当然这里仅仅是标记
return this;
}我们再来看看重置方法:
public final Buffer reset() {
int m = mark; //存一下当前的mark位置
if (m < 0) //因为mark默认是-1,要是没有进行过任何标记操作,那reset个毛
throw new InvalidMarkException();
position = m; //直接让position变成mark位置
return this;
}那比如我们在读取到1号位置时进行标记:

接着我们使用reset方法就可以直接回退回去了:

现在我们来测试一下:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
buffer.get(); //读取一位,那么position就变成1了
buffer.mark(); //这时标记,那么mark = 1
buffer.get(); //又读取一位,那么position就变成2了
buffer.reset(); //直接将position = mark,也就是变回1
System.out.println(buffer.get());
}可以看到,读取的位置根据我们的操作进行了变化,有关缓冲区的读操作,就暂时讲到这里。
缓冲区其他操作
前面我们大致了解了一下缓冲区的读写操作,那么我们接着来看看,除了常规的读写操作之外,还有哪些其他的操作:
public abstract IntBuffer compact()- 压缩缓冲区,由具体实现类实现public IntBuffer duplicate()- 复制缓冲区,会直接创建一个新的数据相同的缓冲区public abstract IntBuffer slice()- 划分缓冲区,会将原本的容量大小的缓冲区划分为更小的出来进行操作public final Buffer rewind()- 重绕缓冲区,其实就是把position归零,然后mark变回-1public final Buffer clear()- 将缓冲区清空,所有的变量变回最初的状态
我们先从压缩缓冲区开始看起,它会将整个缓冲区的大小和数据内容变成position位置到limit之间的数据,并移动到数组头部:
public IntBuffer compact() {
int pos = position(); //获取当前位置
int lim = limit(); //获取当前最大position位置
assert (pos <= lim); //断言表达式,position必须小于最大位置,肯定的
int rem = (pos <= lim ? lim - pos : 0); //计算pos距离最大位置的长度
System.arraycopy(hb, ix(pos), hb, ix(0), rem); //直接将hb数组当前position位置的数据拷贝到头部去,然后长度改成刚刚计算出来的空间
position(rem); //直接将position移动到rem位置
limit(capacity()); //pos最大位置修改为最大容量
discardMark(); //mark变回-1
return this;
}比如现在的状态是:

那么我们在执行 compact()方法之后,会进行截取,此时limit - position = 6,那么就会截取第4、5、6、7、8、9这6个数据然后丢到最前面,接着position跑到7表示这是下一个继续的位置:

现在我们通过代码来检验一下:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 0});
for (int i = 0; i < 4; i++) buffer.get(); //先正常读4个
buffer.compact(); //压缩缓冲区
System.out.println("压缩之后的情况:"+Arrays.toString(buffer.array()));
System.out.println("当前position位置:"+buffer.position());
System.out.println("当前limit位置:"+buffer.limit());
}可以看到最后的结果没有问题:

我们接着来看第二个方法,那么如果我们现在需要复制一个内容一模一样的的缓冲区,该怎么做?直接使用duplicate()方法就可以复制了:
public IntBuffer duplicate() { //直接new一个新的,但是是吧hb给丢进去了,而不是拷贝一个新的
return new HeapIntBuffer(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}那么各位猜想一下,如果通过这种方式创了一个新的IntBuffer,那么下面的例子会出现什么结果:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
IntBuffer duplicate = buffer.duplicate();
System.out.println(buffer == duplicate);
System.out.println(buffer.array() == duplicate.array());
}由于buffer是重新new的,所以第一个为false,而底层的数组由于在构造的时候没有进行任何的拷贝而是直接传递,因此实际上两个缓冲区的底层数组是同一个对象。所以,一个发生修改,那么另一个就跟着变了:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5});
IntBuffer duplicate = buffer.duplicate();
buffer.put(0, 66666);
System.out.println(duplicate.get());
}现在我们接着来看下一个方法,slice()方法会将缓冲区进行划分:
public IntBuffer slice() {
int pos = this.position(); //获取当前position
int lim = this.limit(); //获取position最大位置
int rem = (pos <= lim ? lim - pos : 0); //求得剩余空间
return new HeapIntBuffer(hb, //返回一个新的划分出的缓冲区,但是底层的数组用的还是同一个
-1,
0,
rem, //新的容量变成了剩余空间的大小
rem,
pos + offset); //可以看到offset的地址不再是0了,而是当前的position加上原有的offset值
}虽然现在底层依然使用的是之前的数组,但是由于设定了offset值,我们之前的操作似乎变得不太一样了:

回顾前面我们所讲解的内容,在读取和存放时,会被ix方法进行调整:
protected int ix(int i) {
return i + offset; //现在offset为4,那么也就是说逻辑上的i是0但是得到真实位置却是4
}
public int get() {
return hb[ix(nextGetIndex())]; //最后会经过ix方法转换为真正在数组中的位置
}当然,在逻辑上我们可以认为是这样的:

现在我们来测试一下:
public static void main(String[] args) {
IntBuffer buffer = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 0});
for (int i = 0; i < 4; i++) buffer.get();
IntBuffer slice = buffer.slice();
System.out.println("划分之后的情况:"+Arrays.toString(slice.array()));
System.out.println("划分之后的偏移地址:"+slice.arrayOffset());
System.out.println("当前position位置:"+slice.position());
System.out.println("当前limit位置:"+slice.limit());
while (slice.hasRemaining()) { //将所有的数据全部挨着打印出来
System.out.print(slice.get()+", ");
}
}可以看到,最终结果:

最后两个方法就比较简单了,我们先来看rewind(),它相当于是对position和mark进行了一次重置:
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}接着是clear(),它相当于是将整个缓冲区回归到最初的状态了:
public final Buffer clear() {
position = 0; //同上
limit = capacity; //limit变回capacity
mark = -1;
return this;
}到这里,关于缓冲区的一些其他操作,我们就讲解到此。
缓冲区比较
缓冲区之间是可以进行比较的,我们可以看到equals方法和compareTo方法都是被重写了的,我们首先来看看equals方法,注意,它是判断两个缓冲区剩余的内容是否一致:
public boolean equals(Object ob) {
if (this == ob) //要是两个缓冲区是同一个对象,肯定一样
return true;
if (!(ob instanceof IntBuffer)) //类型不是IntBuffer那也不用比了
return false;
IntBuffer that = (IntBuffer)ob; //转换为IntBuffer
int thisPos = this.position(); //获取当前缓冲区的相关信息
int thisLim = this.limit();
int thatPos = that.position(); //获取另一个缓冲区的相关信息
int thatLim = that.limit();
int thisRem = thisLim - thisPos;
int thatRem = thatLim - thatPos;
if (thisRem < 0 || thisRem != thatRem) //如果剩余容量小于0或是两个缓冲区的剩余容量不一样,也不行
return false;
//注意比较的是剩余的内容
for (int i = thisLim - 1, j = thatLim - 1; i >= thisPos; i--, j--) //从最后一个开始倒着往回比剩余的区域
if (!equals(this.get(i), that.get(j)))
return false; //只要发现不一样的就不用继续了,直接false
return true; //上面的比较都没问题,那么就true
}
private static boolean equals(int x, int y) {
return x == y;
}那么我们按照它的思路来验证一下:
public static void main(String[] args) {
IntBuffer buffer1 = IntBuffer.wrap(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 0});
IntBuffer buffer2 = IntBuffer.wrap(new int[]{6, 5, 4, 3, 2, 1, 7, 8, 9, 0});
System.out.println(buffer1.equals(buffer2)); //直接比较
buffer1.position(6);
buffer2.position(6);
System.out.println(buffer1.equals(buffer2)); //比较从下标6开始的剩余内容
}可以看到结果就是我们所想的那样:

那么我们接着来看比较,compareTo方法,它实际上是Comparable接口提供的方法,它实际上比较的也是pos开始剩余的内容:
public int compareTo(IntBuffer that) {
int thisPos = this.position(); //获取并计算两个缓冲区的pos和remain
int thisRem = this.limit() - thisPos;
int thatPos = that.position();
int thatRem = that.limit() - thatPos;
int length = Math.min(thisRem, thatRem); //选取一个剩余空间最小的出来
if (length < 0) //如果最小的小于0,那就返回-1
return -1;
int n = thisPos + Math.min(thisRem, thatRem); //计算n的值当前的pos加上剩余的最小空间
for (int i = thisPos, j = thatPos; i < n; i++, j++) { //从两个缓冲区的当前位置开始,一直到n结束
int cmp = compare(this.get(i), that.get(j)); //比较
if (cmp != 0)
return cmp; //只要出现不相同的,那么就返回比较出来的值
}
return thisRem - thatRem; //如果没比出来个所以然,那么就比长度
}
private static int compare(int x, int y) {
return Integer.compare(x, y);
}这里我们就不多做介绍了。