ThreadLocal的使用
既然每个线程都有一个自己的工作内存,那么能否只在自己的工作内存中创建变量仅供线程自己使用呢?
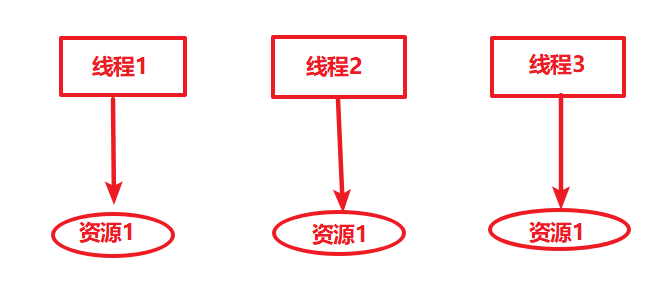
我们可以使用ThreadLocal类,来创建工作内存中的变量,它将我们的变量值存储在内部(只能存储一个变量),不同的线程访问到ThreadLocal对象时,都只能获取到当前线程所属的变量。
public static void main(String[] args) throws InterruptedException {
ThreadLocal<String> local = new ThreadLocal<>(); //注意这是一个泛型类,存储类型为我们要存放的变量类型
Thread t1 = new Thread(() -> {
local.set("lbwnb"); //将变量的值给予ThreadLocal
System.out.println("变量值已设定!");
System.out.println(local.get()); //尝试获取ThreadLocal中存放的变量
});
Thread t2 = new Thread(() -> {
System.out.println(local.get()); //尝试获取ThreadLocal中存放的变量
});
t1.start();
Thread.sleep(3000); //间隔三秒
t2.start();
}上面的例子中,我们开启两个线程分别去访问ThreadLocal对象,我们发现,第一个线程存放的内容,第一个线程可以获取,但是第二个线程无法获取,我们再来看看第一个线程存入后,第二个线程也存放,是否会覆盖第一个线程存放的内容:
public static void main(String[] args) throws InterruptedException {
ThreadLocal<String> local = new ThreadLocal<>(); //注意这是一个泛型类,存储类型为我们要存放的变量类型
Thread t1 = new Thread(() -> {
local.set("lbwnb"); //将变量的值给予ThreadLocal
System.out.println("线程1变量值已设定!");
try {
Thread.sleep(2000); //间隔2秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1读取变量值:");
System.out.println(local.get()); //尝试获取ThreadLocal中存放的变量
});
Thread t2 = new Thread(() -> {
local.set("yyds"); //将变量的值给予ThreadLocal
System.out.println("线程2变量值已设定!");
});
t1.start();
Thread.sleep(1000); //间隔1秒
t2.start();
}我们发现,即使线程2重新设定了值,也没有影响到线程1存放的值,所以说,不同线程向ThreadLocal存放数据,只会存放在线程自己的工作空间中,而不会直接存放到主内存中,因此各个线程直接存放的内容互不干扰。
我们发现在线程中创建的子线程,无法获得父线程工作内存中的变量:
public static void main(String[] args) {
ThreadLocal<String> local = new ThreadLocal<>();
Thread t = new Thread(() -> {
local.set("lbwnb");
new Thread(() -> {
System.out.println(local.get());
}).start();
});
t.start();
}我们可以使用InheritableThreadLocal来解决:
public static void main(String[] args) {
ThreadLocal<String> local = new InheritableThreadLocal<>();
Thread t = new Thread(() -> {
local.set("lbwnb");
new Thread(() -> {
System.out.println(local.get());
}).start();
});
t.start();
}在InheritableThreadLocal存放的内容,会自动向子线程传递。
定时器
我们有时候会有这样的需求,我希望定时执行任务,比如3秒后执行,其实我们可以通过使用Thread.sleep()来实现:
public static void main(String[] args) {
new TimerTask(() -> System.out.println("我是定时任务!"), 3000).start(); //创建并启动此定时任务
}
static class TimerTask{
Runnable task;
long time;
public TimerTask(Runnable runnable, long time){
this.task = runnable;
this.time = time;
}
public void start(){
new Thread(() -> {
try {
Thread.sleep(time);
task.run(); //休眠后再运行
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}我们通过自行封装一个TimerTask类,并在启动时,先休眠3秒钟,再执行我们传入的内容。那么现在我们希望,能否循环执行一个任务呢?比如我希望每隔1秒钟执行一次代码,这样该怎么做呢?
public static void main(String[] args) {
new TimerLoopTask(() -> System.out.println("我是定时任务!"), 3000).start(); //创建并启动此定时任务
}
static class TimerLoopTask{
Runnable task;
long loopTime;
public TimerLoopTask(Runnable runnable, long loopTime){
this.task = runnable;
this.loopTime = loopTime;
}
public void start(){
new Thread(() -> {
try {
while (true){ //无限循环执行
Thread.sleep(loopTime);
task.run(); //休眠后再运行
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}现在我们将单次执行放入到一个无限循环中,这样就能一直执行了,并且按照我们的间隔时间进行。
但是终究是我们自己实现,可能很多方面还没考虑到,Java也为我们提供了一套自己的框架用于处理定时任务:
public static void main(String[] args) {
Timer timer = new Timer(); //创建定时器对象
timer.schedule(new TimerTask() { //注意这个是一个抽象类,不是接口,无法使用lambda表达式简化,只能使用匿名内部类
@Override
public void run() {
System.out.println(Thread.currentThread().getName()); //打印当前线程名称
}
}, 1000); //执行一个延时任务
}我们可以通过创建一个Timer类来让它进行定时任务调度,我们可以通过此对象来创建任意类型的定时任务,包延时任务、循环定时任务等。我们发现,虽然任务执行完成了,但是我们的程序并没有停止,这是因为Timer内存维护了一个任务队列和一个工作线程:
public class Timer {
/**
* The timer task queue. This data structure is shared with the timer
* thread. The timer produces tasks, via its various schedule calls,
* and the timer thread consumes, executing timer tasks as appropriate,
* and removing them from the queue when they're obsolete.
*/
private final TaskQueue queue = new TaskQueue();
/**
* The timer thread.
*/
private final TimerThread thread = new TimerThread(queue);
...
}TimerThread继承自Thread,是一个新创建的线程,在构造时自动启动:
public Timer(String name) {
thread.setName(name);
thread.start();
}而它的run方法会循环地读取队列中是否还有任务,如果有任务依次执行,没有的话就暂时处于休眠状态:
public void run() {
try {
mainLoop();
} finally {
// Someone killed this Thread, behave as if Timer cancelled
synchronized(queue) {
newTasksMayBeScheduled = false;
queue.clear(); // Eliminate obsolete references
}
}
}
/**
* The main timer loop. (See class comment.)
*/
private void mainLoop() {
try {
TimerTask task;
boolean taskFired;
synchronized(queue) {
// Wait for queue to become non-empty
while (queue.isEmpty() && newTasksMayBeScheduled) //当队列为空同时没有被关闭时,会调用wait()方法暂时处于等待状态,当有新的任务时,会被唤醒。
queue.wait();
if (queue.isEmpty())
break; //当被唤醒后都没有任务时,就会结束循环,也就是结束工作线程
...
}newTasksMayBeScheduled实际上就是标记当前定时器是否关闭,当它为false时,表示已经不会再有新的任务到来,也就是关闭,我们可以通过调用cancel()方法来关闭它的工作线程:
public void cancel() {
synchronized(queue) {
thread.newTasksMayBeScheduled = false;
queue.clear();
queue.notify(); //唤醒wait使得工作线程结束
}
}因此,我们可以在使用完成后,调用Timer的cancel()方法以正常退出我们的程序:
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
timer.cancel(); //结束
}
}, 1000);
}守护线程
注意: 不要把操作系统中的守护进程和守护线程相提并论。
操作系统中的守护进程在后台运行,不需要和用户交互,本质和普通进程类似。而守护线程就不一样了,当其他所有的非守护线程结束之后,守护线程自动结束,也就是说,Java中所有的线程都执行完毕后,守护线程自动停止,因此守护线程不适合进行IO操作,只适合打打杂:
public static void main(String[] args) throws InterruptedException{
Thread t = new Thread(() -> {
while (true){
try {
System.out.println("程序正常运行中...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.setDaemon(true); //设置为守护线程(必须在开始之前,中途是不允许转换的)
t.start();
for (int i = 0; i < 5; i++) {
Thread.sleep(1000);
}
}在守护线程中产生的新线程也是守护的:
public static void main(String[] args) throws InterruptedException{
Thread t = new Thread(() -> {
Thread it = new Thread(() -> {
while (true){
try {
System.out.println("程序正常运行中...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
it.start();
});
t.setDaemon(true); //设置为守护线程(必须在开始之前,中途是不允许转换的)
t.start();
for (int i = 0; i < 5; i++) {
Thread.sleep(1000);
}
}再谈集合类
因为多线程的加入,我们之前认识的集合类都废掉了:
public static void main(String[] args) throws InterruptedException {
List<Integer> list = new ArrayList<>();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
list.add(i); //两个线程同时操作集合类进行插入操作
}
}).start();
new Thread(() -> {
for (int i = 1000; i < 2000; i++) {
list.add(i);
}
}).start();
Thread.sleep(2000);
System.out.println(list.size());
}我们发现,有些时候运气不好,得到的结果并不是2000个元素,而是:

因为之前的集合类,并没有考虑到多线程运行的情况,如果两个线程同时执行,那么有可能两个线程同一时间都执行同一个方法,这种情况下就很容易出问题:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 当数组容量更好还差一个满的时候,这个时候两个线程同时走到了这里,因为都判断为没满,所以说没有进行扩容,但是实际上两个线程都要插入一个元素进来
elementData[size++] = e; //当两个线程同时在这里插入元素,直接导致越界访问
return true;
}当然,在Java早期的时候,还有一些老的集合类,这些集合类都是线程安全的:
public static void main(String[] args) throws InterruptedException {
Vector<Integer> list = new Vector<>(); //我们可以使用Vector代替List使用
//Hashtable<Integer, String> 也可以使用Hashtable来代替Map
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
list.add(i);
}
}).start();
new Thread(() -> {
for (int i = 1000; i < 2000; i++) {
list.add(i);
}
}).start();
Thread.sleep(1000);
System.out.println(list.size());
}因为这些集合类中的每一个方法都加了锁,所以说不会出现多线程问题,但是这些老的集合类现在已经不再使用了,我们会在JUC篇视频教程中介绍专用于并发编程的集合类。
通过对Java多线程的了解,我们就具备了利用多线程解决问题的思维!
(Java 8) 并行流
集合类中有一个东西是Java8新增的Spliterator接口,翻译过来就是:可拆分迭代器(Splitable Iterator)和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行而设计的。Java 8已经为集合框架中包含的所有数据结构提供了一个默认的Spliterator实现。在集合跟接口Collection中提供了一个spliterator()方法用于获取可拆分迭代器。
其实我们之前在讲解集合类的根接口时,就发现有这样一个方法:
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true); //parallelStream就是利用了可拆分迭代器进行多线程操作
}并行流,其实就是一个多线程执行的流,它通过默认的ForkJoinPool实现(这里不讲解原理),它可以提高你的多线程任务的速度。
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 4, 5, 2, 9, 3, 6, 0));
list
.parallelStream() //获得并行流
.forEach(i -> System.out.println(Thread.currentThread().getName()+" -> "+i));
}我们发现,forEach操作的顺序,并不是我们实际List中的顺序,同时每次打印也是不同的线程在执行!我们可以通过调用forEachOrdered()方法来使用单线程维持原本的顺序:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 4, 5, 2, 9, 3, 6, 0));
list
.parallelStream() //获得并行流
.forEachOrdered(System.out::println);
}我们之前还发现,在Arrays数组工具类中,也包含大量的并行方法:
public static void main(String[] args) {
int[] arr = new int[]{1, 4, 5, 2, 9, 3, 6, 0};
Arrays.parallelSort(arr); //使用多线程进行并行排序,效率更高
System.out.println(Arrays.toString(arr));
}更多地使用并行方法,可以更加充分地发挥现代计算机多核心的优势,但是同时需要注意多线程产生的异步问题。
public static void main(String[] args) {
int[] arr = new int[]{1, 4, 5, 2, 9, 3, 6, 0};
Arrays.parallelSetAll(arr, i -> {
System.out.println(Thread.currentThread().getName());
return arr[i];
});
System.out.println(Arrays.toString(arr));
}实战:生产者与消费者
所谓的生产者消费者模型,是通过一个容器来解决生产者和消费者的强耦合问题。通俗的讲,就是生产者在不断的生产,消费者也在不断的消费,可是消费者消费的产品是生产者生产的,这就必然存在一个中间容器,我们可以把这个容器想象成是一个货架,当货架空的时候,生产者要生产产品,此时消费者在等待生产者往货架上生产产品,而当货架有货物的时候,消费者可以从货架上拿走商品,生产者此时等待货架出现空位,进而补货,这样不断的循环。
通过多线程编程,来模拟一个餐厅的2个厨师和3个顾客,假设厨师炒出一个菜的时间为3秒,顾客吃掉菜品的时间为4秒。
(Java 21) 线程生成器
Java 21为我们新增了一个ofPlatform()方法,它可以快速生成一个创建平台线程(就是我们上面介绍的线程,下面还会介绍虚拟线程)的线程生成器:
Thread.ofPlatform()
.name("线程01") //直接调用方法设置线程的相关属性
.daemon(true) //是否为守护线程
.priority(Thread.MAX_PRIORITY) //设置优先级
.inheritInheritableThreadLocals(false) //是否允许InheritableThreadLocal继承数据
.start(() -> { //配置好后一键启动
System.out.println("Hello World");
});使用此线程生成器帮我们创建线程来的更快更直接一点。
对于线程内发生的异常,我们还可以为其指定异常处理器,通过调用uncaughtExceptionHandler方法来指定:
Thread.ofPlatform()
.uncaughtExceptionHandler((t, exception) -> {
System.out.println("检测到线程执行中出现异常: " + exception);
})
.start(() -> {
throw new RuntimeException("我出事了!");
});此外,我们还可以为线程设定其堆栈大小。这个堆栈是什么意思呢,由于现在各位小伙伴还没有学习JVM底层原理,这里就简单给大家解释一下。假设现在我们执行这样的代码:
public static void main(String[] args) {
test1();
}
private static void test1() {
test2();
}
private static void test2() {
System.out.println("我是最里面");
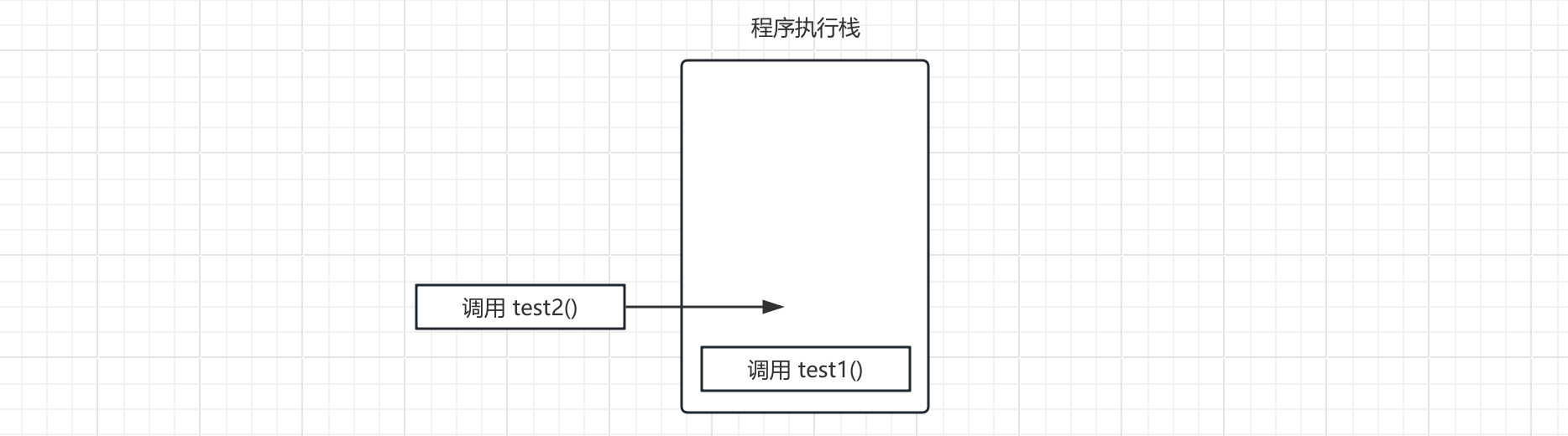
}可以看到,我们在main方法内调用test1方法,然后test1内又调用test2方法,在方法的调用过程中,实际上有一个专门的栈结构,在储存方法的调用和其参数。我们每向下调用一次方法,那么方法信息以及其携带的参数就会进栈,像这样的东西我们一般称为"栈帧",然后等待位于最顶上的方法执行完毕:
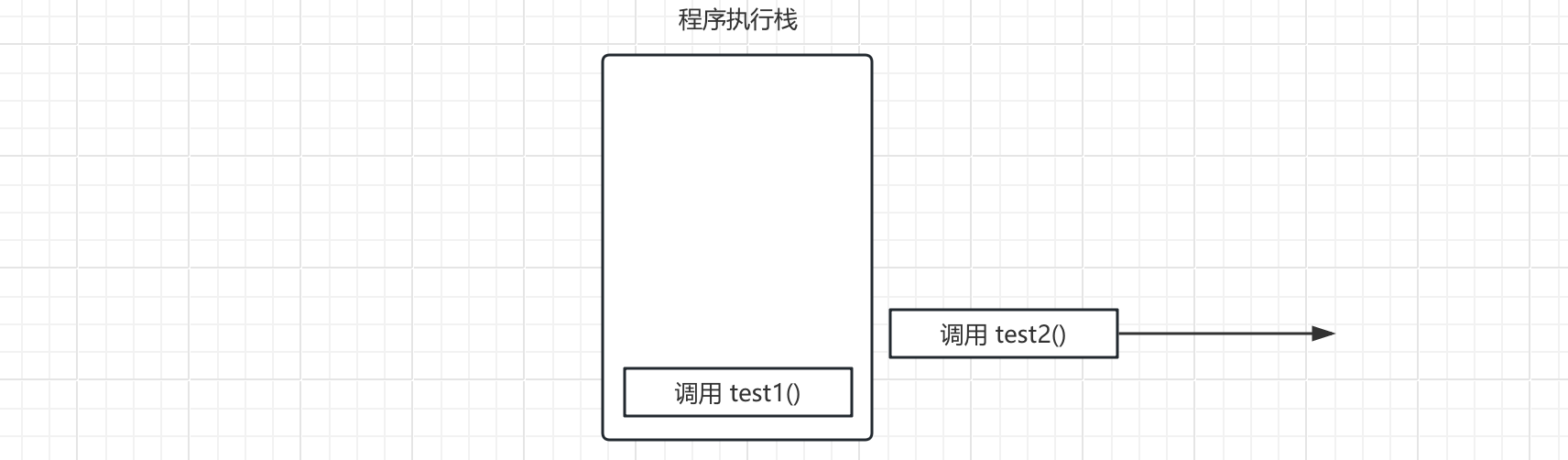
当最顶上的方法结束之后,栈中的对应的栈帧便会离开,从而继续执行下一个位于栈顶的方法:
大致原理就是这样,程序的执行需要用到栈来维护秩序。不过栈的深度是有限制的,就像我们之前使用递归的形式调用方法,如果不加以限制,那么栈中将无限制插入栈帧,这肯定会出现问题。默认情况下,栈的深度由JVM自动设定,我们也可以手动干预每个线程的最大栈深度:
public static void main(String[] args) {
Thread.ofPlatform()
.start(Main::test1);
}
public static int i = 0;
private static void test1() { //写个递归无限往下
System.out.println(i++); //打印i来查看调用深度
test1();
}
默认情况下,在深度达到30000左右时出现了爆栈的情况(不同的系统可能结果不一样)我们可以通过配置stackSize来建议此线程使用多大的栈空间:
public static void main(String[] args) {
Thread.ofPlatform()
.stackSize(1024 * 1024 * 10) //空间大小,单位为Byte,这里给了10MB
.start(Main::test1);
}重新执行后,可以看到,调用深度比刚刚大了不少:

不过这个参数只是建议,如果给的过大或者过小都会强制使用预设的最大最小值。
(Java 21) 虚拟线程
虚拟线程(Virtual Threads)是Java在JDK 19中引入的一项新特性,旨在简化并发编程模型,提升高并发应用的性能和可扩展性,此功能最终在Java 21版本实装上线。
虚拟线程是Java中的一种轻量级线程,由Java虚拟机(JVM)管理,与我们之前介绍的传统的操作系统级线程(Platform Threads)相比,它免去了平台线程的CPU的上下文切换,而是由程序在线程内自行控制,消耗的资源更少,启动和切换速度更快,进而可以在同一物理线程上并发执行大量虚拟线程。其核心优势为:
- 高并发能力:数以万计的虚拟线程可以在少量的操作系统线程上并发执行,极大提升应用的并发能力。
- 简化编程模型:开发者可以使用同步的阻塞式代码编写异步或高并发逻辑,无需手动管理复杂的回调或异步框架。
- 资源效率:虚拟线程内存占用较少,启动速度快,有助于构建高性能的服务器和微服务。
综上,虚拟线程实际上是在单个线程内进一步细分的产物:
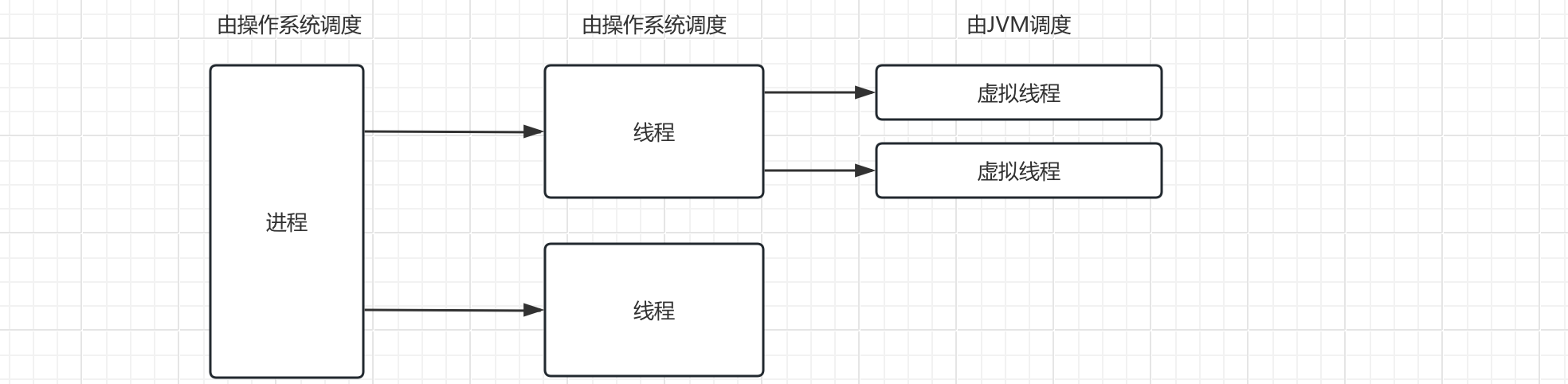
线程在Java中分为两种:
- 平台线程: 就是我们上面讲解的线程,由操作系统进行调度。
- 虚拟线程: 本节介绍的由JVM在线程内部调度的线程。
创建虚拟线程非常简单,直接使用startVirtualThread方法即可,它和线程的用法是一样的:
Thread.startVirtualThread(() -> {
System.out.println("我是虚拟线程");
});注意,虚拟线程和平台线程不一样,它默认就是守护线程且不能修改,也就是说主线程结束它也会跟着结束,所以上面的代码我们执行之后不会出现任何内容。我们需要使用join在主线程等待其完成:
Thread.startVirtualThread(() -> {
System.out.println("我是虚拟线程");
}).join();
除此之外,我们也可以使用生成器创建虚拟线程:
Thread.ofVirtual()
.name("虚拟线程 01")
.start(() -> System.out.println("我真的是虚拟线程"));注意,虚拟线程不支持使用stop结束线程,调用会报错。有关虚拟线程的实现原理和更多用法,我们会在JUC篇和Java学习路线的后续课程中逐步介绍。
反射
注意: 本章节涉及到JVM相关底层原理,难度会有一些大。
反射就是把Java类中的各个成分映射成一个个的Java对象。即在运行状态中,对于任意一个类,都能够知道这个类所有的属性和方法,对于任意一个对象,都能调用它的任意一个方法和属性。这种动态获取信息及动态调用对象方法的功能叫Java的反射机制。
简而言之,我们可以通过反射机制,获取到类的一些属性,包括类里面有哪些字段,有哪些方法,继承自哪个类,甚至还能获取到泛型!它的权限非常高,慎重使用!
Java类加载机制
在学习Java的反射机制之前,我们需要先了解一下类的加载机制,一个类是如何被加载和使用的:

在Java程序启动时,JVM会将一部分类(class文件)先加载(并不是所有的类都会在一开始加载),通过ClassLoader将类加载,在加载过程中,会将类的信息提取出来(存放在元空间中,JDK1.8之前存放在永久代),同时也会生成一个Class对象存放在内存(堆内存),注意此Class对象只会存在一个,与加载的类唯一对应!
为了方便各位小伙伴理解,你们就直接理解为默认情况下(仅使用默认类加载器)每个类都有且只有一个唯一的Class对象存放在JVM中,我们无论通过什么方式访问,都是始终是那一个对象。Class对象中包含我们类的一些信息,包括类里面有哪些方法、哪些变量等等。
Class类获取
通过前面,我们了解了类的加载,同时会提取一个类的信息生成Class对象存放在内存中,而反射机制其实就是利用这些存放的类信息,来获取类的信息和操作类。那么如何获取到每个类对应的Class对象呢,我们可以通过以下方式:
public static void main(String[] args) throws ClassNotFoundException {
Class<String> clazz = String.class; //使用class关键字,通过类名获取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class类静态方法forName(),通过包名.类名获取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass(); //通过实例对象获取
}注意Class类也是一个泛型类,只有第一种方法,能够直接获取到对应类型的Class对象,而以下两种方法使用了?通配符作为返回值,但是实际上都和第一个返回的是同一个对象:
Class<String> clazz = String.class; //使用class关键字,通过类名获取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class类静态方法forName(),通过包名.类名获取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass();
System.out.println(clazz == clazz2);
System.out.println(clazz == clazz3);通过比较,验证了我们一开始的结论,在JVM中每个类始终只存在一个Class对象,无论通过什么方法获取,都是一样的。现在我们再来看看这个问题:
public static void main(String[] args) {
Class<?> clazz = int.class; //基本数据类型有Class对象吗?
System.out.println(clazz);
}迷了,不是每个类才有Class对象吗,基本数据类型又不是类,这也行吗?实际上,基本数据类型也有对应的Class对象(反射操作可能需要用到),而且我们不仅可以通过class关键字获取,其实本质上是定义在对应的包装类中的:
/**
* The {@code Class} instance representing the primitive type
* {@code int}.
*
* @since JDK1.1
*/
@SuppressWarnings("unchecked")
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");
/*
* Return the Virtual Machine's Class object for the named
* primitive type
*/
static native Class<?> getPrimitiveClass(String name); //C++实现,并非Java定义每个包装类中(包括Void),都有一个获取原始类型Class方法,注意,getPrimitiveClass获取的是原始类型,并不是包装类型,只是可以使用包装类来表示。
public static void main(String[] args) {
Class<?> clazz = int.class;
System.out.println(Integer.TYPE == int.class);
}通过对比,我们发现实际上包装类型都有一个TYPE,其实也就是基本类型的Class,那么包装类的Class和基本类的Class一样吗?
public static void main(String[] args) {
System.out.println(Integer.TYPE == Integer.class);
}我们发现,包装类型的Class对象并不是基本类型Class对象。
数组类型也是一种类型,只是编程不可见,因此我们可以直接获取数组的Class对象:
public static void main(String[] args) {
Class<String[]> clazz = String[].class;
System.out.println(clazz.getName()); //获取类名称(得到的是包名+类名的完整名称)
System.out.println(clazz.getSimpleName());
System.out.println(clazz.getTypeName());
System.out.println(clazz.getClassLoader()); //获取它的类加载器
System.out.println(clazz.cast(new Integer("10"))); //强制类型转换
}下节课,我们将开始对Class对象的使用进行讲解。