
计算机网络基础
温馨提示: 在开启本课程之前,请先完成JavaSE基础篇视频课程以及Java9-17新特性篇(可选),本次课程全程采用Java17版本进行讲解,从这里开始将不会再对任何Java基础语法知识进行讲解,因此JavaSE基础篇请完全掌握后再来。
从JavaWeb篇开始,我们的Java后端学习之路就正式进入到新手村啦,不过根据咱们之前课程中的观察,发现有些小伙伴在学习的过程中存在一些问题,希望大家在开启之前提前摆正心态:
- 课程时间比较短,课程中每一个知识点都是我们浓缩的精华内容,不建议跳过任何部分,不要为了去省时间就跳着看,因为你到后面复习八股文的时候还是会回来补,反而浪费更多时间,所以为什么不一开始就学好呢。
- 在看视频的过程中,不要只是跟着敲一遍能让程序运行就行,而是要时刻清楚你自己在写什么,这个东西有什么用。很多小伙伴在学习完一套课程之后还是什么都不会写,无法独立去编写程序,这是因为脑子里没有对自己学习的内容形成概念。
- 如果观看过程中发现有任何自己不太清楚的知识点,必须立即查清楚(无论什么方式)不要看得一脸懵逼了还在强行继续看,这样不仅浪费你自己的时间,还学不到任何东西,只会让你的欠债越来越多,到后面越学越难。
接着我们还需要各位小伙伴提前开始准备以下开发工具:
- Navicat Premium Lite - 学习数据库必备工具
- IntelliJ IDEA Ultimate - JavaWeb之后学习开发的必备工具
- Chrome - 浏览器,开发专用浏览器
以上所有的都准备好之后,咱们就可以开始愉快的JavaWeb学习之旅啦~

走进网络世界
从网络诞生的那一天开始,我们的世界变得完全不一样了。
曾经人们需要跋涉千里才能将一封信送到家人手中,一条重要的消息可能需要很多天的时间才能传达,而现在我们只需要使用手机即可轻松发送一条微信给我们的家人,千里之外的商品也可以直接在App上下单,微博上的新闻也是第一时间霸榜,而这些几乎都是实时的。
网络的起源可以追溯到20世纪60年代初,当时美国国防部的高级研究计划署(ARPA)在进行一项名为ARPANET的项目,旨在建立一种去中心化的通讯网络,来实现军事和科研机构之间的信息交流。ARPANET是世界上第一个广域网,于1969年建立了第一个节点,通过分组交换数据的方式实现了信息传输。
随着时间的推移,ARPANET不仅连接了更多的节点,还演变成了现代互联网的雏形。在1970年代和1980年代,出现了TCP/IP协议奠定了互联网的基础,域名系统(DNS)的建立也增加了互联网的易用性。
1990年代互联网开始向公众开放,世界各地的人们可以通过浏览器访问网页、发送电子邮件等方式使用互联网。随着技术的不断进步和普及,互联网已经成为现代社会中不可或缺的一部分,极大地改变了人们的生活方式和工作方式。
而我们要学习的Java后端开发,就与网络有着密不可分的关系。为了各位小伙伴学习简单,我们不会上来就讲解计算机网络的专业知识点,首先还是从身边的网络设备开始给大家进行介绍,让大家逐渐对网络形成一个认识,以及了解我们主要的学习方向。
互联网和网络设备介绍
当我们想要查资料时,可以在浏览器中打开百度,只需输入我们想要查找的内容就可以了。当我们想要娱乐时,只需打开对应的游戏即可和其他小伙伴一起联机。当我们想听歌时,只需要打开音乐软件就能快速播放。实际上它们都是互联网上提供的服务,我们只需要连接到互联网,就可以随时随地享受这些服务,非常方便。
现如今,互联网上有着数以万计的网站、应用程序、游戏等,网络可以说是我们身边必不可少的东西,截至2023年12月,中国网民规模达10.92亿人,较2022年12月新增网民2480万人,互联网普及率达77.5%,在我们身边几乎每个人都会上网,并且全世界任何一个角落的人都可以访问到互联网上的内容。
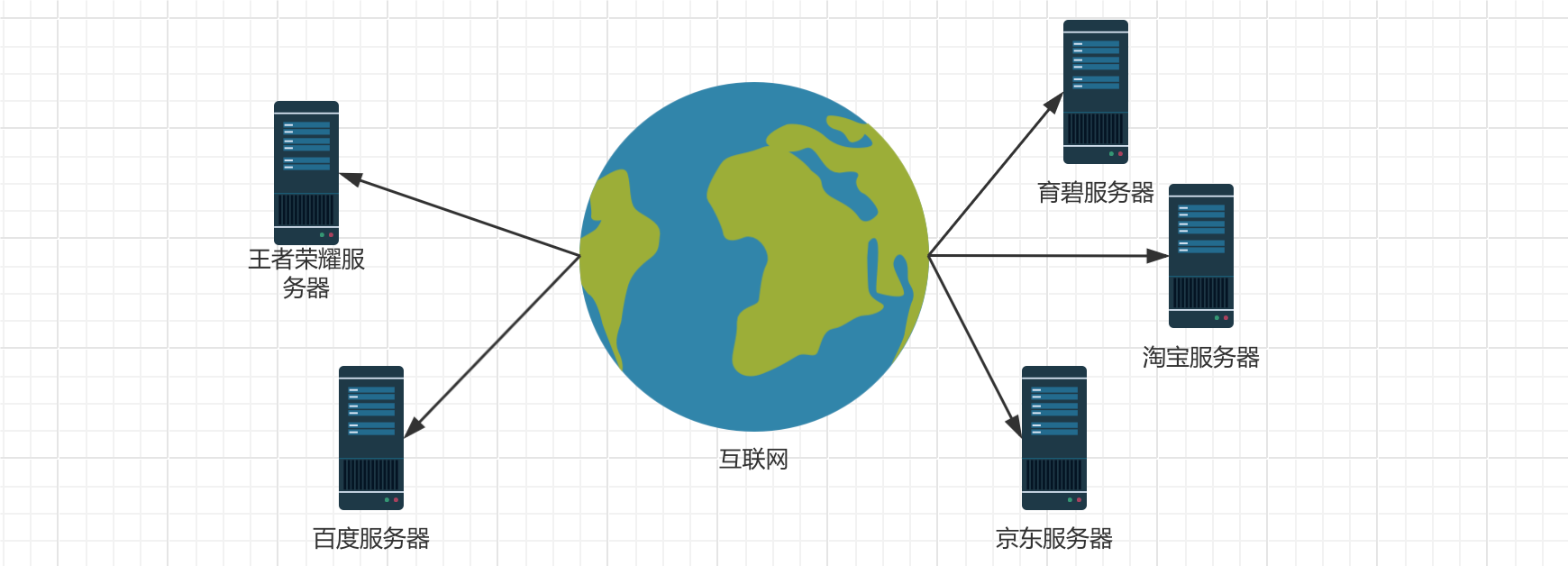
我们做开发的主要方向,就是这些互联网上的内容,比如网站之类的,而网站开发又分为前端开发和后端开发,前端开发负责提供网页的外观、用户交互设计等,也就是客户端,而后端则需要为前端提供数据,前端拿到之后在页面中展示,有关详细的内容我们会在后续课程中逐步介绍。
那么我们作为用户来说是如何连接到互联网的呢?普通公民是没办法直接接入到互联网的,一般只能通过一些网络运营商(网络服务供应商,ISP)来接入到互联网,一般比较常见的有以下几种方式:
- 办理运营商的SIM卡套餐,并插入到支持SIM卡的手机或平板设备,这样就能接入到附近的基站上使用5G或4G网络,随时随地只要附近有基站信号都可以使用。
- 办理运营商的宽带套餐,一般是光纤入户,通过将小区的光纤接入到家里,实现居家上网,这种网络接入方式相比4G/5G网络延迟更低更稳定,缺点就是位置是固定的。
目前我国一共有四大运营商:

我们首先来看家里的宽带上网,运营商会在小区里部署一系列的光纤设备(有些在小区花园,有些在楼道内)这些设备与互联网相连接,我们在办理套餐之后,会有专门的工程师为我们接入,这里就不得不提到光猫和路由器了:
- 光猫: 光纤入户的必备设备,一般办理宽带套餐之后运营商会直接增送一个(不用千万别扔了,退宽带的时候还要还的)由于光纤中数据以光作为媒介进行传输,而我们的电脑、手机只能接收电信号,因此我们需要通过一个设备将不同信号类型进行转换,而光猫就是做这个事情的。
- 路由器: 由于我们家里有着非常多的设备,它们都需要连接网络,但是光猫提供的有线网口太少,而且不支持无限连接,比如我们最常见的WiFi信号,这些功能都可以由路由器来提供,它可以同时连接多个网络的设备并将数据准确发送到互联网,不过现在有一部分运营商的光猫自带路由器功能,也支持WiFi信号发射,但是大部分用户还是会选择单独安装一个路由器使用,毕竟更加专业和稳定。
所以,在我们的家中使用互联网,架构一般就像下面这样:
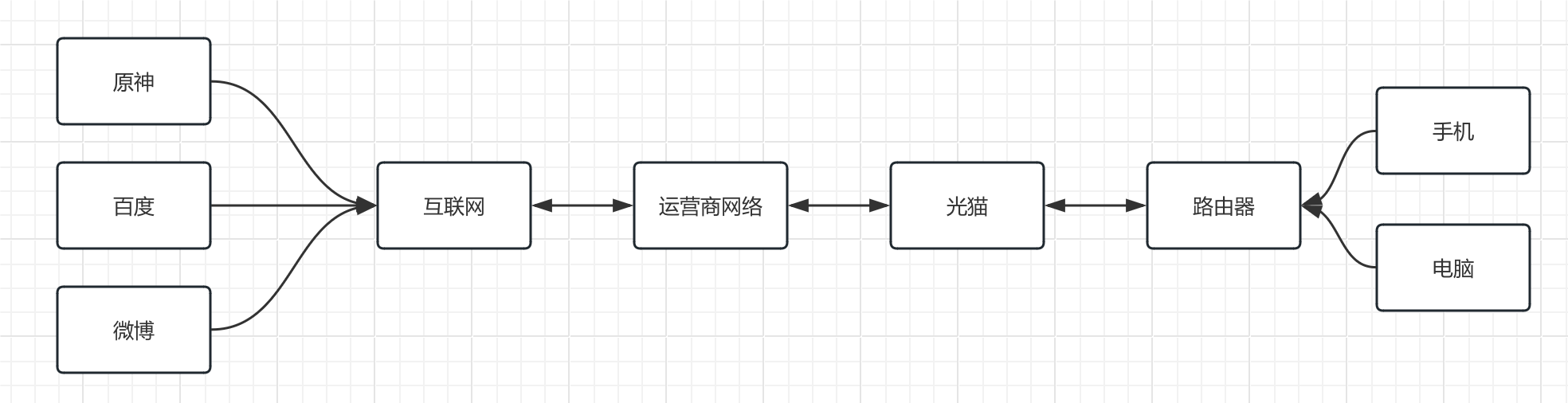
通过这样层层连接,我们就可以愉快地上网了。
IP地址和端口
前面给大家介绍我们身边常见的一些网络设备,以及大概的连接结构,相信各位小伙伴一定有一些认识了。
我们接着来看IP地址,在生活中,我们每家每户都有一个门牌号,这样当别人来找我们时,就可以根据地址快速找到我们在什么位置(比如送外卖、送快递等)而在互联网中,我们如果要访问某个站点或者是某个站点要向我们发送数据,怎么确定是谁呢,所以每一个设备同样有着自己的地址,我们现在最常用的就是IP地址。
我们通过WiFi或者网线连接路由器时,会自动获得一个IP地址(通过DHCP协议自动分配),大家可以打开自己的电脑或手机,在设置中查看自己的IP地址:
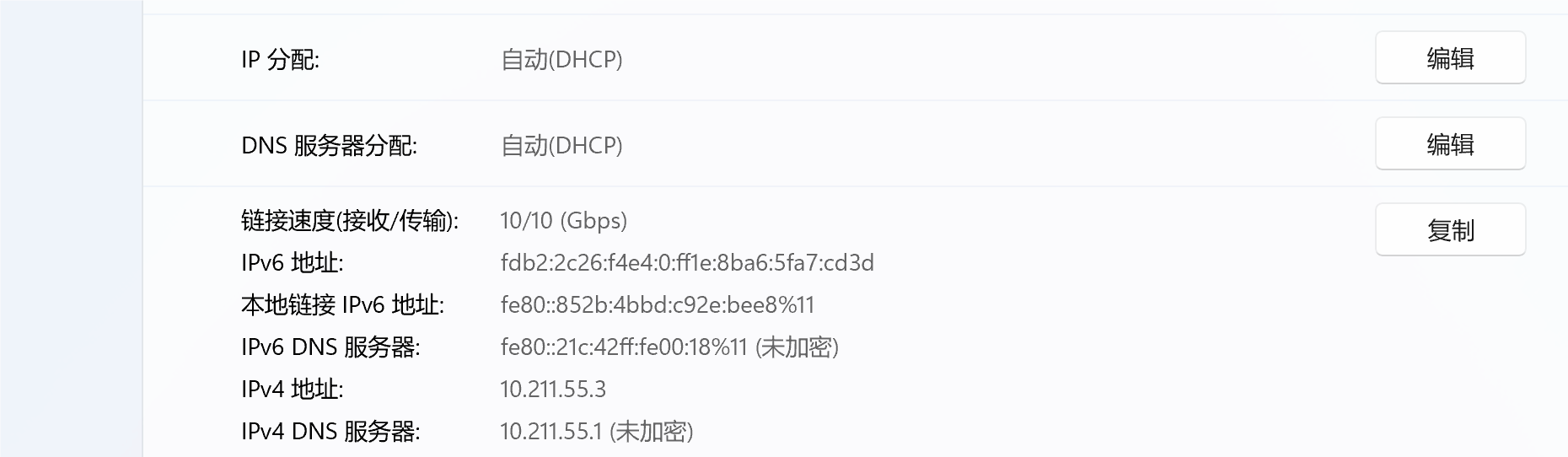
IP地址一共有两种,一种是IPv4地址,各位小伙伴看到的大概率都是192.168.XX.XX这样的格式,为什么是这样的格式呢,和学习Java基础一样,我们还是回到计算机底层去一步一步研究,实际上它以二进制形式来表示长这样:
192.168.0.5 = 11000000.10101000.00000000.00000101
可以看到,一个IPv4地址一共有4段,每段8个bit位,一共32位,和基本类型int一致。也就是说,IPv4能够表示的地址范围,以十进制表示就是:0.0.0.0到255.255.255.255,理论上如果全部拿来使用的话,大约有43亿个地址可用。
但是实际上我们能够使用的地址非常有限,国际上根据不同类型的网络用途,对网段进行了划分,主要分为 A、B、C、D、E 五类,每类地址都有其特定的用途和特点:
- A类地址:以0开头,网络地址空间长度为7位,主机地址空间长度为24位。A类地址的范围是从1.0.0.0到127.255.255.255。A类IP地址适用于有大量主机的大型网络,每个A类网络的主机地址数多达16,000,000个。
- B类地址:以10开头,网络地址空间长度为14位,主机地址空间长度为16位。B类IP地址的范围是从128.0.0.0到191.255.255.255。B类地址适用于一些国际性大公司与政府机构等,每个B类网络的主机地址数多达65536个。
- C类地址:以110开头,网络地址空间长度为21位,主机地址空间长度为8位。C类IP地址的范围是从192.0.0.0到223.255.255.255。C类IP地址特别适用于一些小公司与普通的研究机构,每个C类网络的主机地址数最多为256个。
- D类地址:以1110开头,不标识网络,用于其他特殊的用途,如多目的地址。D类IP地址的范围是从224.0.0.0到239.255.255.255。
- E类地址:以11110开头,暂时保留用于某些实验和将来使用。E类IP地址的范围是从240.0.0.0到255.255.255.255。
各位小伙伴可以试想一下,虽然IPv4地址能够表示的范围已经很广了,但是随着我们科技的发展,越来越多的设备要加入到互联网中,如果所有设备都分配一个独一无二的IP地址,那么肯定是不够用的,所以说在我们国家,一般很少会给个人一个可以直接使用的IP地址(我们也称为公网IP地址,也就是在互联网中的一个独一无二的IP地址)实际上我们家里的宽带上网,一般都是一个小区一栋楼或者一整个小区共用一个IP地址去与互联网上的资源交互。而路由器分配给我们的IP地址,实际上是一个局域网IP地址,局域网顾名思义就是一个局部的网络,这个网络是独立的,所有IP地址也仅仅属于这个局域网内部,就像下面这样:
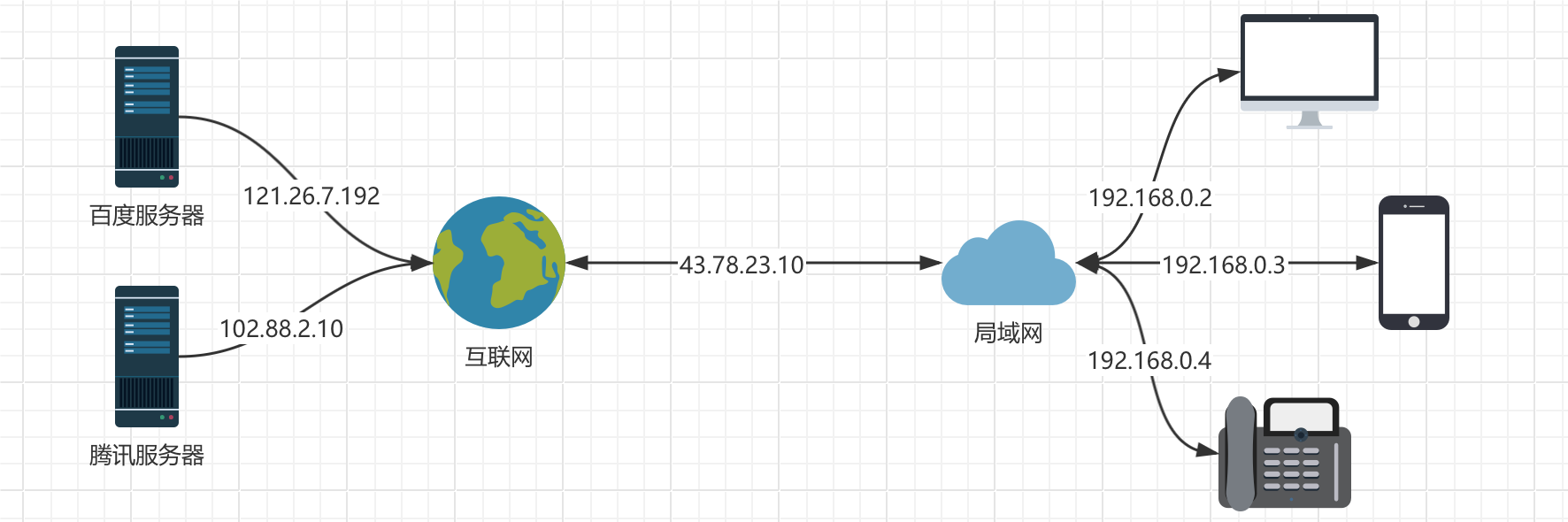
各位小伙伴可以在百度直接搜索"IP"这两个字母,然后就可以看到运营商分配给你的公网IP地址了,同时可以回顾一下之前系统设置中看到的IP地址,是不是发现不一样?路由器给我们分配的地址是局域网内的,仅限于所有连接到此路由器的设备之间可以相互通信。
还有一种是IPv6地址,它的优势就在于它大大地扩展了地址的可用空间,由于IPv4容量太小,很容易被用完,很难做到一机一IP,到目前为止只有一些欧美国家能够做到一户一IP,在其他国家都是小区共享公网IP,而IPv6的出现解决了这个问题,它一般长这样:
2001:0db8:85a3:0000:0000:8a2e:0370:7334
fe80::5
IPv6一共有128位,其中每个16位为一组,以十六进制表示,一共8组,一个IPv6地址中间可能全部都是0,为了简便可以把连续的一段0缩写为"::",但为保证地址解析的唯一性,地址中"::"只能出现一次。
不过在现在来看,IPv6普及率还远不及IPv4,很多网站现在还不支持使用IPv6访问,甚至有些宽带师傅安装时根本不给你开通IPv6功能,所以说目前我们主要还是以使用IPv4为主,后续课程也是以IPv4作为讲解。
我们接着来看下一个重要的内容,端口。我们的手机和电脑在联网之后,虽然可以获得一个IP地址与其他设备通信,但是各位小伙伴可以想一下,我们的电脑上运行着各种各样的软件,这些软件可能会找不同的IP地址进行通信,但是我们只获得了一个IP地址,如果其他设备要给我们电脑上某个应用发送数据,那怎么辨别呢?
端口是计算机网络中用来识别应用程序和服务的逻辑通道。在网络通信中,每一个计算机都会有一个或多个端口,用于传输数据和与其他计算机进行通信。每个端口都有一个数字来标识,常见的端口号范围是0到65535,其中0到1023是系统保留端口,用于一些常见的服务,比如HTTP服务使用的端口80,FTP服务使用的端口21等,在Linux或MacOS下普通用户无权使用。
通过端口,不同的应用程序可以同时在计算机上运行并与其他设备进行通信。
端口的出现解决了我们电脑上不同应用的网络通信问题,所以说两台设备之间相互通信,实际上并不是两个IP地址直接互相访问,而是对应的程序之间,选择并使用一个特定的端口来进行通信,就像这样:
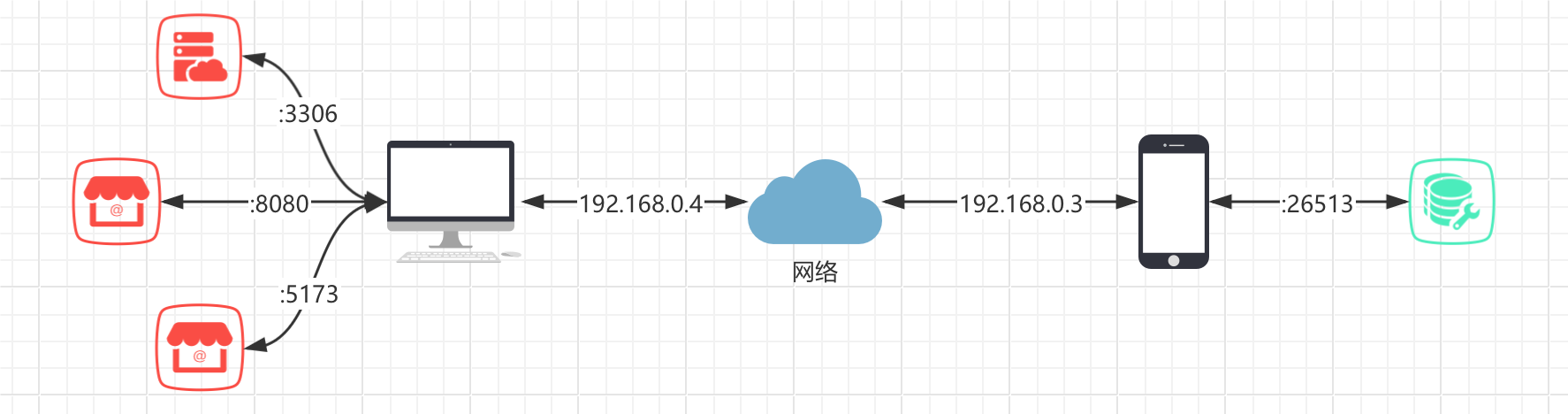
包括我们前面说到的小区用户共用一个公网IP地址一样,如何去区分不同的家庭或是某台设备,其实都是通过端口来进行区分的:
NAT(Network Address Translation)设备可以通过端口转换(Port Mapping)来区分内网不同IP地址。在NAT设备中,端口是用来标识不同连接的,当内网多个主机访问外部服务器时,NAT设备会将每个内网主机的请求映射到不同的端口,然后转发给外部服务器。外部服务器根据不同的端口来区分来自不同内网主机的请求,并将响应数据发送回相应的端口,最后NAT设备将响应数据转发给对应的内网主机。这样就实现了区分内网不同IP地址的功能。
域名和DNS
前面我们了解了互联网上每台设备都有一个自己的IP地址,同样的,百度也有一个自己的IP地址,但是一串IP地址实在是太难记了(很多人连手机号都记不住还记啥IP呢)我们一般不会用它的IP地址直接去访问,而是使用一个更容易记忆的网址来表示:https://www.baidu.com,这实际上是百度的域名。
域名是用来代表互联网资源(例如网站、服务器等)的名称。它通常由一个顶级域名(比如.com、.org、.net等)和一个二级域名(比如example.com)组成。域名可以让人们更容易记住和访问特定的网站或资源,类似于互联网的地址标识符。通过向域名系统(DNS)查询,域名最终会被转换成一个IP地址,从而帮助用户定位到相应的互联网资源。
很多我们常见的网站,比如:baidu.com,taobao.com,google.com等,这些其实都是顶级域名.com下的一系列二级域名,我们作为个人或是企业,可以直接申请一个顶级域名下的二级域名使用,名字可以随便起,哪怕是中文都可以,申请方式很简单,价格也很便宜:

域名注册采用的是先来后到的机制,谁先注册域名就归谁,比如我们的梦想中的域名就是itbaima.com,但是很可惜已经被别人给注册了,去年蹲了半年都没给蹲到,只能被迫使用其他域名。
有了域名之后,我们可以选择一个受信任的DNS服务器配置域名解析,一般腾讯云、阿里云这种云服务商自家就有,配置起来很方便,最简单的就是配置让域名指向一个IP地址,这样,当别人使用浏览器访问一个域名时,浏览器会先从DNS服务器请求这个域名指向的IP地址,然后浏览器再去请求这个IP地址上的资源。
大家可以尝试访问一下百度,然后按下键盘上的F12按键:
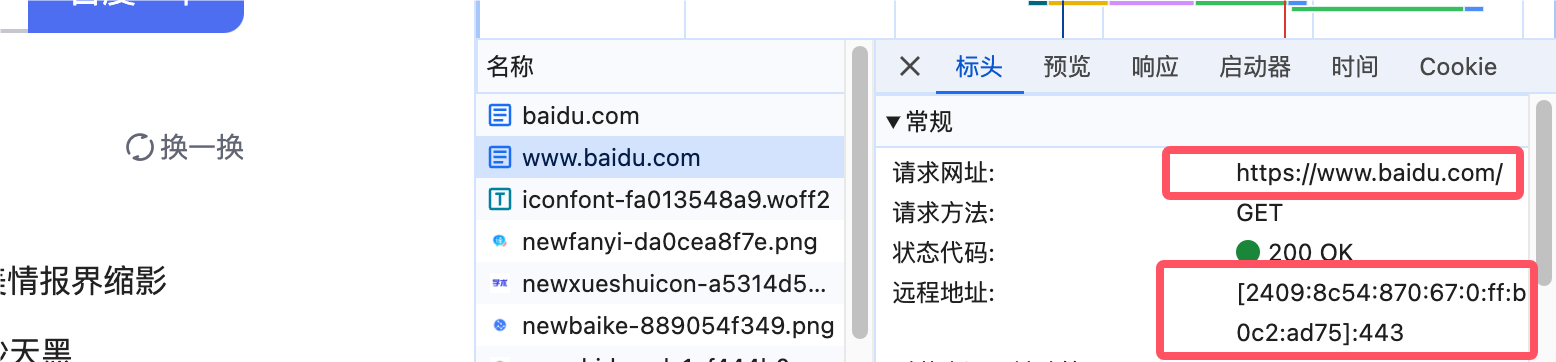
此时找到最上方的www.baidu.com这个请求,我们就可以看到通过DNS解析得到的远程地址了,各位小伙伴可能会看到一个IPv4的地址,或是一个IPv6的地址,由于IPv6优先级更高,如果你们看到的是一个IPv6的地址,那么说明你家的网络是支持IPv6的,否则只支持IPv4网络。
除了这种方式之外,也可以使用ping命令直接查看某个域名解析的IP地址和访问延迟:

由于谷歌被墙,在大陆是无法成功访问的。
网络通信协议
前面我们给大家简单介绍了网络设备和IP地址、端口以及域名解析等内容,相信各位小伙伴已经对我们使用的网络有了一定初步的认识,这一部分我们将继续深入探讨基于网络之上的通信协议,尤其是HTTP协议,这将是贯穿我们整个Java后端开发甚至是前端Web开发路线的核心内容。
那么,什么是通信协议呢?通信协议是指双方实体完成通信或服务所必须遵循的规则和约定。比如我们古代的长城,每隔50米到100米都有烽火台,当其中任何一个烽火台发现有敌情,士兵们都可以点着烟火,当其他烽火台发现时,就可以马上知道出现了问题。

而这里其实就是通信协议的一种体现,这实际上就是士兵们在开战之前商量好的通信方式以及通信内容的含义。
在我们计算机的网络通信中,不同设备或是软件之间通讯,也需要一定的通信协议,这样才能使得网络通信高效和有序地进行,在介绍常见的通信协议之前,我们先来看一下一个数据包在网络中是如何传输的。
OSI七层网络模型
OSI(开放系统互连)七层模型是一个网络框架,通过将通信系统划分为七个不同的层次,简化网络设计和实施。每层都有其特定的功能,独立于其他层,但协同工作以确保数据通信的完整性和效率。这里我们为各位小伙伴简单介绍一下大致内容,好让各位有一个基本的概念。
-
应用层(Application Layer)
- 功能:直接与最终用户交互,为应用程序提供网络服务。
- 常见协议:HTTP, FTP, SMTP, SNMP, DNS, Telnet。
我们常见的各种应用程序,都是工作在应用层,这也是我们本课程主要的学习方向。
-
表示层(Presentation Layer)
- 功能:数据格式化,转换,和数据加密,确保数据能被应用层正确读取和理解。
- 常见功能:数据压缩、加密与解密、数据格式转换。
-
会话层(Session Layer)
- 功能:负责建立、管理和终止会话(通信连接)。
- 常见功能:会话管理、全双工、半双工、和单工操作模式、会话检查点和恢复功能。
-
传输层(Transport Layer)
- 功能:提供端到端的通信控制,确保数据可靠传输。
- 常见协议:TCP, UDP。
- 常见功能:流量控制、错误检测与纠正、数据重传。
传输层也是我们需要重要学习的内容
-
网络层(Network Layer)
- 功能:负责路由和转发数据包,处理逻辑地址(如IP地址)。
- 常见协议:IP, ICMP, ARP, RARP。
- 常见设备:路由器。
-
数据链路层(Data Link Layer)
- 功能:提供节点到节点间的传输,处理物理寻址(MAC地址)、错误检测和纠正。
- 常见协议:Ethernet, PPP, HDLC。
- 常见设备:交换机,网桥。
-
物理层(Physical Layer)
- 功能:定义了物理设备的电气和物理规范,如线缆类型,连接器,频率等。
- 常见标准:RJ45, Ethernet,光纤标准。
可能各位小伙伴看到这七层模型一脸懵逼,没关系,我们先从最顶层来看看一个应用程序的数据包是如何在网络中传输的,实际上这是一个逐层封装的过程,每一层都会为我们的数据包添加额外的数据头部信息,包含当前层的相关信息:
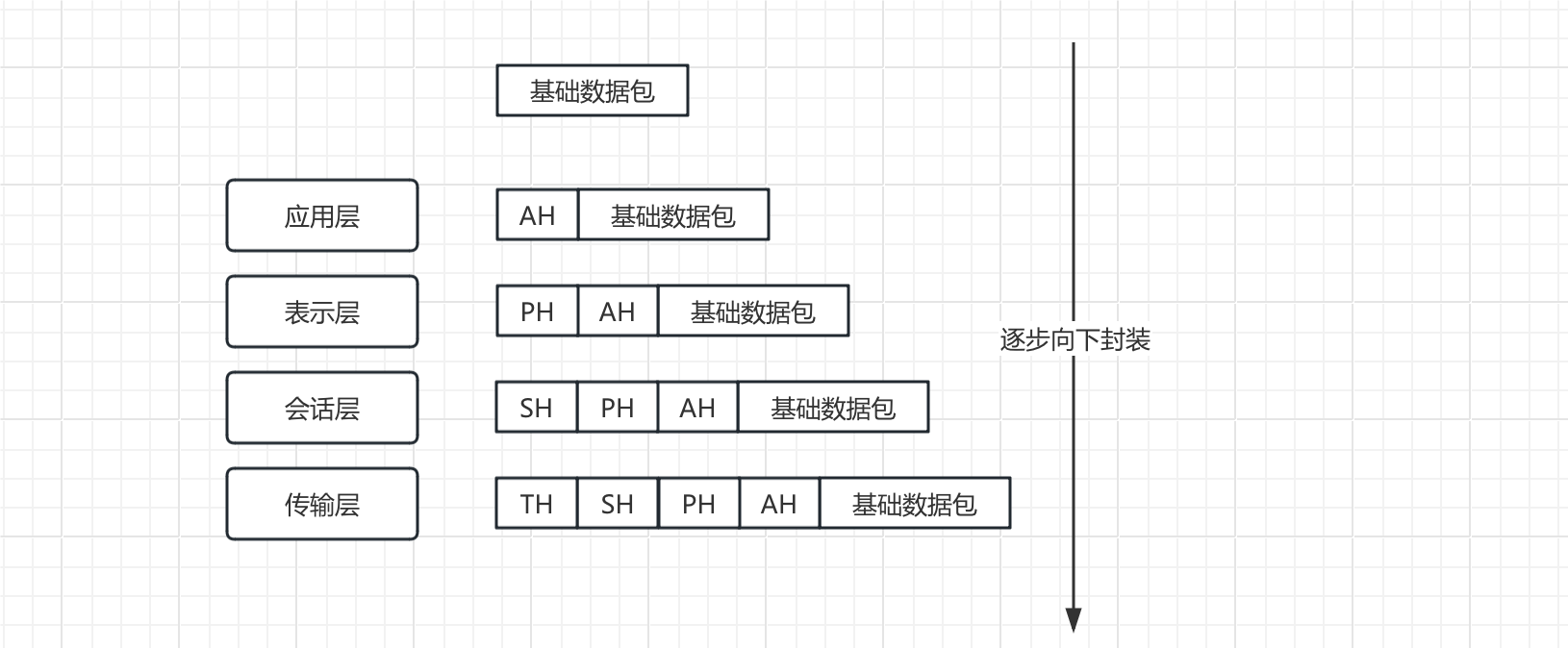
不难发现,数据包从应用层开始向下逐层封装,经过各层的处理后得到一个最终的数据包。那么为什么要像这样去进行处理呢?实际上这是为了让每一层分工明确,做好自己分内的事情。
首先是应用层,这是七层模型的最高层,我们编写的Web应用程序基本都是工作在这一层,向用户提供各种网络应用服务,包括文件传输、电子邮件、网页浏览等。这一层需要关心的就是应用之间如何通信,还记得我们之前介绍的什么是通信协议吗,以HTTP协议为例,它就一个典型的应用层通信协议,我们的数据包采用HTTP协议发送时,会为其添加对应的头部信息,包括但不限于浏览器的类型、数据格式、当前的网站地址等。当对方在收到我们的HTTP数据包时,就可以直接从头部信息中读取这些数据,从而快速得知另一方需要回复什么内容。

同样的,在网络层也会对数据包添加对应的头部信息,比如我们这个数据包要发送的目标IP地址等信息,方便其他网络设备对数据包进行正确的路由和转发。

经过不断的封装,已经成型的数据包接着会通过网络传输介质传输到目标主机,然后再反向逐层解封装,最终交付给目标主机的应用层进行处理:
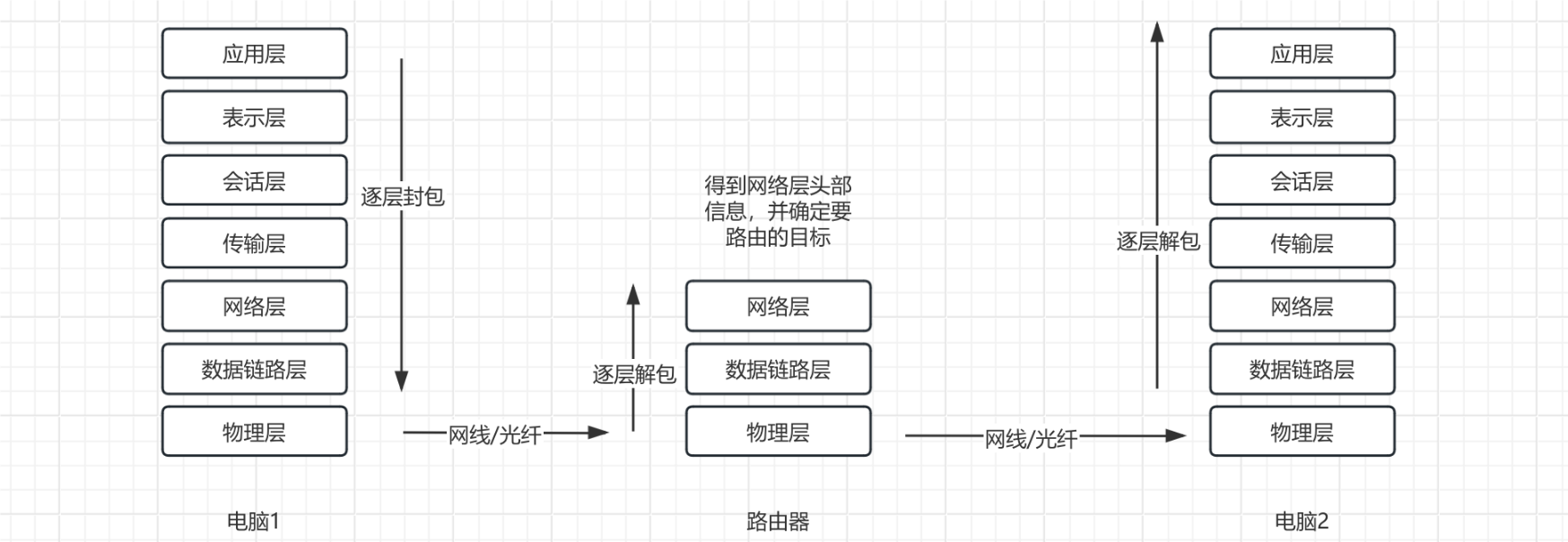
在了解完七层网络模型之后,相信各位小伙伴心中肯定有了一定的概念,实际上每一层都有着一些通信协议用于数据收发,我们接着来详细介绍一些比较重要的通信协议。
TCP协议
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层协议。TCP协议在互联网中起着非常重要的作用,它保证了数据的可靠传输,通过数据确认、重传机制和拥塞控制来确保数据的完整性和可靠性。TCP协议的特点包括:
- 面向连接:在数据传输前需要建立连接,在数据传输结束后需要释放连接。
- 可靠性:通过数据确认和重传机制,确保数据能够按照正确的顺序到达目的地。
- 拥塞控制:通过拥塞窗口和慢启动等机制,避免网络拥塞和数据丢失。
- 全双工通信:允许双方同时发送和接收数据。
- 流量控制:根据接收方的处理能力,控制发送数据的速度,避免数据丢失。
TCP是我们传输层的常用协议之一,通信双方可以使用TCP协议建立连接,连接建立之后就可以互发数据了,它的最大特性就是可靠连接,为什么可靠,我们先从TCP连接的建立说起。要建立一个TCP连接,并不是直接告诉对方我们要开始发数据就完事的,它会经历几个阶段:
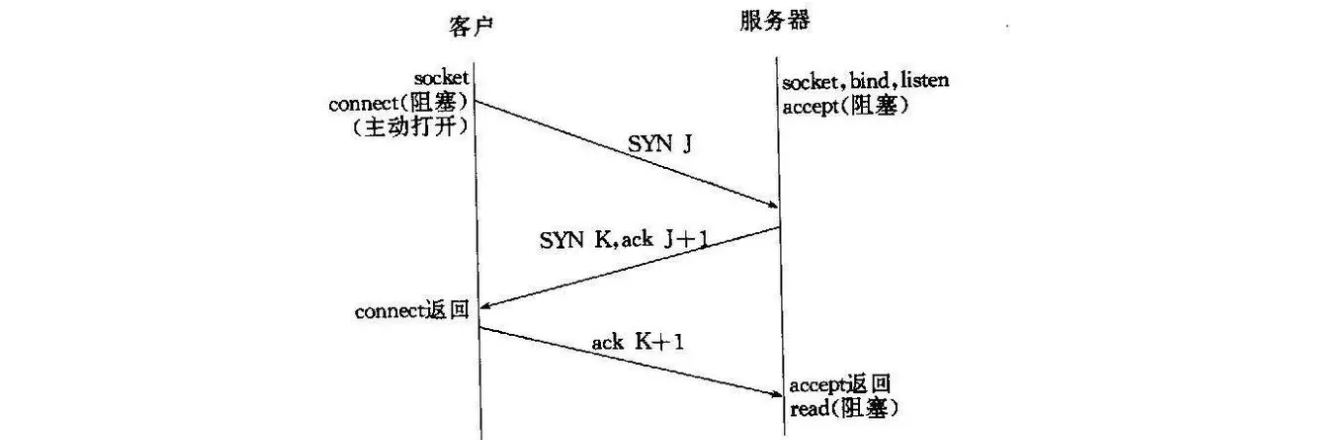
建立TCP连接时主要包括以下三个步骤:
- 第一步:客户端向服务器发送SYN(同步)包,请求建立连接。客户端发送的包中包含一个初始序列号,用于数据传输的顺序编号。
- 第二步:服务器接收到客户端发送的SYN包后,向客户端发送 SYN + ACK 包作为应答。服务器发送的包中除了确认客户端的SYN包外,还会发送自己的初始化序列号。
- 第三步:客户端接收到服务器发送的 SYN + ACK 包后,向服务器发送 ACK 包以确认连接。这时TCP连接建立成功,双方可以开始传输数据了。
可以看到,要建立一个TCP连接需要传递三次数据包(三次握手)才能完成,为什么要设计得怎么复杂呢,我们说TCP是一个可靠连接,一定要验证连接是可靠的,是可以相互顺利发送数据的,如果缺少这三次的任意一次,会发生什么?
- 如果只进行一次握手,我们无法确定对方是否收到了我们的数据包或是对方的环境可以建立可靠连接,这种情况下如果强行建立连接的话,肯定是无法保证稳定性的。
- 如果只进行两次握手,也就是说收到对方返回的ACK之后就建立连接的话,看似没问题,但是对方无法确定我们是否收到的其确认信息,这对我们来说确实没问题,但是对方慌得一匹啊,对方不知道这个数据包是否成功被我们收到,万一网络有问题我们这边真的没收到数据包呢。
因此,三次握手任何一步都不能忽略,这样才能保证可靠连接。
那么三次握手机制我们了解了,我们接着来看TCP连接是如何结束的,这里就要讲到四次挥手了:
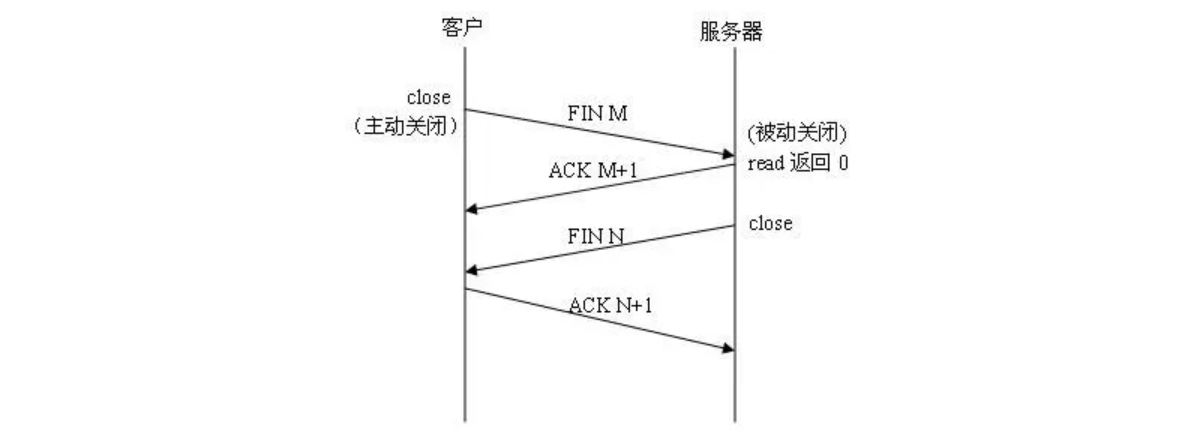
关闭TCP连接时主要包含以下步骤:
- 第一步:客户端(或主动关闭方)发送一个带有FIN(完成)标志的报文段给服务器,表示它已经完成数据的发送工作,不再需要保持连接。
- 第二步:服务器(或被动关闭方)接收到FIN报文,回复一个带有ACK(Acknowledgment)标志的报文段,表明它已经收到关闭请求,但是由于连接可能还在使用,比如有数据包还没发完之类的,所以此时不会立即关闭。
- 第三步:服务器处理完手头剩下的事情后,发送一个带有FIN标志的报文段给客户端,表示它也准备好关闭连接。
- 第四步:客户端收到服务器的FIN报文,发送一个带有ACK标志的报文段作为最终确认。此时,客户端进入
TIME_WAIT状态,一段时间后才真正关闭连接,目的是确保服务器能够收到ACK报文。
可以看到,要关闭一个TCP连接相比建立来说,更加复杂,它一共需要发送四次数据包(四次挥手)那么为什么要设计得这么复杂呢?我们还是来一步一步分析:
- 如果只进行一次挥手,也就是客户端直接跟服务端说我们分手,服务端此时可能根本没收到关闭的信息,客户端就直接关闭了,这显然不符合TCP连接可靠稳定的标准,所以跟握手一样,肯定要等回复。
- 如果只进行两次挥手,也就是说当服务端回复之后,客户端直接关闭连接,虽然这样能确定对方也想关闭连接,但是此时可能还有一些数据没发送完成,如果贸然关闭会导致数据发一半就没了,同样不符合TCP连接可靠稳定的标准。
- 如果只进行三次挥手,也就是此时对方已经发送了ACK和FIN信息了,此时客户端确实可以放心大胆关闭了,但是服务端这边依然无法确定客户端是否可以完全结束,万一客户端还有啥事没办呢(注意第一次挥手只是客户端觉得可以结束然后请求,并不是数据全都发完了,别搞混了)所以说仍有资源泄露或数据丢失的风险,不符合TCP连接可靠稳定的标准。
因此,通过四次挥手,可以确保连接安全可靠地终止,避免数据丢失和资源不足问题,是一个较为完善的设计。
现在我们了解了TCP连接的连接和关闭,我们接着来看TCP连接的数据发送,由于TCP协议是传输层协议,我们前面说过在每一层都会有对应的头部信息拼接到数据包中,TCP协议同样会为数据包添加自己的头部信息:
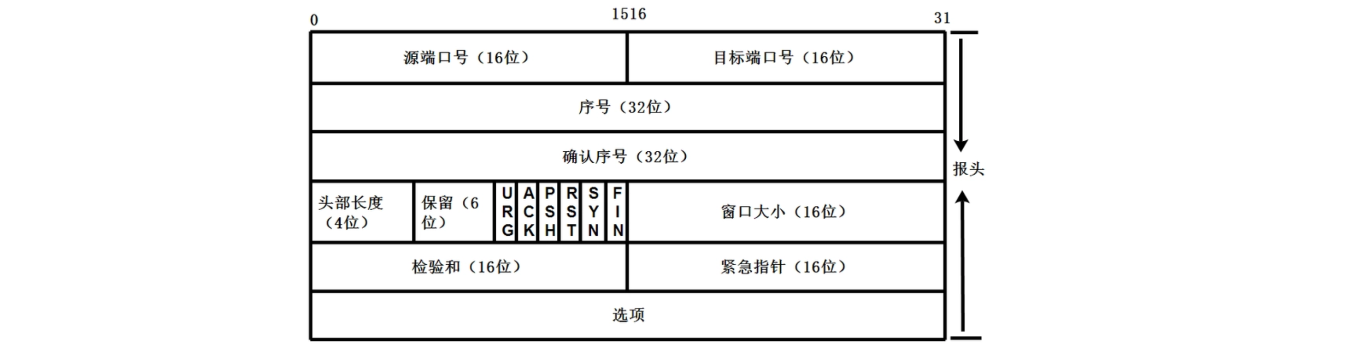
头部信息各个部分介绍如下,大概了解一下就行:
- 源端口(Source Port):16位,用于标识发送端的应用程序或进程。
- 目标端口(Destination Port):16位,用于标识接收端的应用程序或进程。
- 序列号(Sequence Number):32位,标识从发送端向接收端发送的字节流中的第一个字节的位置。
- 确认序列号(Acknowledgment Number):32位,仅在ACK标志为1时有效,指示期望接收的下一个字节的位置,表示已经成功接收到的数据的最后一个字节。
- 数据偏移(Data Offset):4位,表示TCP头部的长度,单位为4字节。该值最小为5,最大可达15,表明TCP头部长度在20到60字节之间。
- 保留(Reserved):3位,保留为将来使用,应设置为0。
- 标志位(Flags,或Control Bits):9位,控制标志包含以下若干子标志:
- URG:紧急指针(urgent pointer)有效。
- ACK:确认序列号有效。
- PSH:接收方应该尽快将数据推送到应用层。
- RST:重置连接。
- SYN:同步序列号,用于建立连接。
- FIN:发送方已完成发送数据,用于终止连接。
- 窗口大小(Window Size):16位,用于流量控制,指示接收方当前能够接收的数据量(以字节为单位)。
- 校验和(Checksum):16位,检验头部和数据的完整性。
- 紧急指针(Urgent Pointer):16位,仅在URG标志有效时使用,指示紧急数据的结束位置。
- 选项(Options):可变长度(最多40字节),用于携带诸如最大报文段长度(MSS)、时间戳等选项。
- 填充(Padding):为了确保TCP头部长度为4字节的整数倍,填充的数据。
那么数据是如何相互发送的呢?这就简单了,每次发送数据只需要给一个响应即可:

当三次握手完成后,此时就可以进行数据发送,我们的应用程序发送数据时,实际上首先会将数据发送到TCP发送缓冲区中,然后,TCP协议栈会负责将这些数据按照协议信息分片、打包,并逐步发送出去。这样可以极大地优化数据的传输效率,可以想像一下一堆很小的数据一个一个发和缓存好了一次性发有什么区别。同样的,接受数据时也可以像这样先缓存一下再一起让应用程序读取。

只不过,虽然这种缓冲机制能够一定程度上优化数据的传输,但是有时候也会造成一些麻烦,最常见的就是数据粘包和拆包问题:
- 发送方可能会为了优化网络效率,将一些小数据包合并成一个更大的数据包发送出去,导致接收方收到的直接就是一个大数据包,但是这可能是两条完全独立的消息。
- 接收方可能会将两个或多个TCP段中的数据合并在一起进行读取,同上。
常用的解决粘包问题的方法包括:
- 定长消息:每个消息都以固定长度发送,接收方只要按照固定长度读取数据即可,但这种方法不适用于可变长度数据。
- 分隔符:在每个消息之间添加特殊的分隔符,接收方可以根据分隔符判断消息的边界。例如,使用
\n或者其他特殊字符。 - 消息头部添加长度信息:在每个消息前增加一个字段表示消息长度,接收方先读取长度字段,然后按照长度字段读取完整消息。
- 应用层协议设计:设计上层协议时,考虑粘包与拆包,通过协议规范解决粘包问题。
至此,后续课程知识储备已足够,有关TCP协议的流量/拥塞控制、超时重传等内容,请参阅计算机网络相关知识,这里不再对其进行详细介绍。
UDP协议
UDP(User Datagram Protocol,用户数据报协议)是一种无连接的、轻量级的传输层协议。UDP相比于TCP,不提供可靠的数据传输、数据流控制和错误恢复,但与TCP相比,UDP的头部较小,只有8字节,由于其简单高效的特点,适用于一些对实时性要求较高、数据传输容忍一定丢失的应用场景,比如:
- 实时音视频传输:如VoIP(Voice over IP)、直播流媒体等。
- DNS查询:UDP被用于域名解析查询,在保持连接性不那么重要的情况下,可以更快速地进行域名解析。
- 简单数据传输:在一些对可靠传输要求不高的应用场景下,UDP可以简化实现,并减少网络开销。
简单粗暴,只需要发,发,发:

我们来看看UDP报文的格式,相比TCP可以说简单了不少。
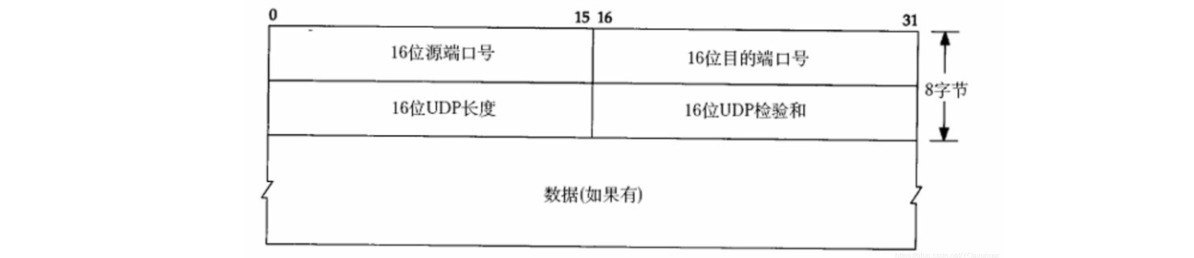
报文格式如下:
- 源端口:占用2个字节,表示UDP报文的源端口号。
- 目的端口:占用2个字节,表示UDP报文的目的端口号。
- 长度:占用2个字节,表示UDP报文的总长度,包括首部和数据部分。
- 校验和:占用2个字节,提供对UDP报文的差错检测。
UDP报文格式简单高效,适合短消息传递等对实时性要求较高的通信场景。由于UDP本身不提供可靠性保证,因此在使用UDP时,应用程序需要自行实现数据完整性校验、丢包重传等机制来保证数据传输的可靠性。
HTTP协议
我们接着来介绍我们最最重要的一个应用层协议,HTTP(Hypertext Transfer Protocol)是一种用于传输超文本信息的协议,它构建在TCP/IP协议之上,是互联网上应用最为广泛的协议之一。我们使用浏览器去浏览一个网站就是使用的HTTP协议进行交互,它的交互过程非常简单,就是客户端发送请求然后服务端给出响应即可:
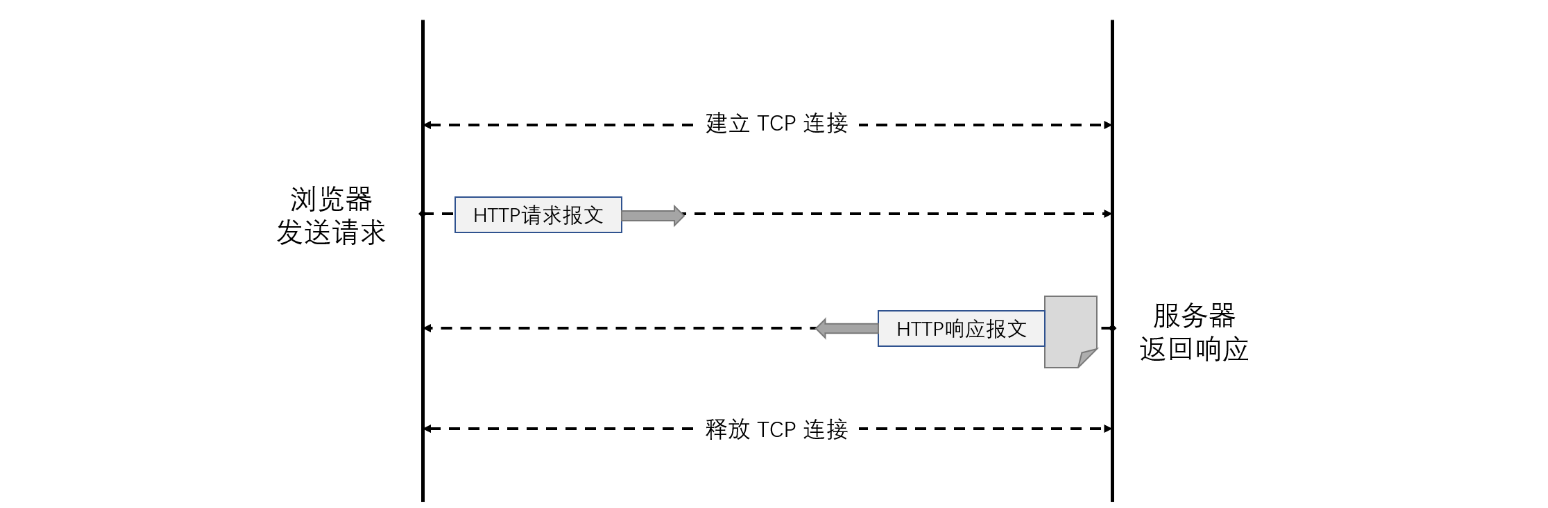
由于HTTP是基于TCP协议实现的,所以在发送请求之前,会提前建立一个TCP连接来保证可靠传输,然后再发送HTTP请求报文,服务端响应之后再关闭TCP连接。
我们接着来看看HTTP请求报文格式,接着我们打开Chrome浏览器,按下电脑键盘上的F12键,此时会打开浏览器的开发者工具面板,接着选择"网络"选项卡,此时没有任何内容:
此外我们之间在浏览器地址栏中输入:http://www.baidu.com,这是访问百度的URL(格式为 <协议>://<主机>:<端口>/<路径>,互联网上所有的资源,都有一个唯一确定的URL)此时浏览器会直接访问百度,并且开发面板中会显示很多的网络请求信息,我们直接选择最上方的www.baidu.com请求,这是浏览器向服务器发出的第一个请求,也是一个网站开始加载的第一步。
我们将请求标头勾选为原始:
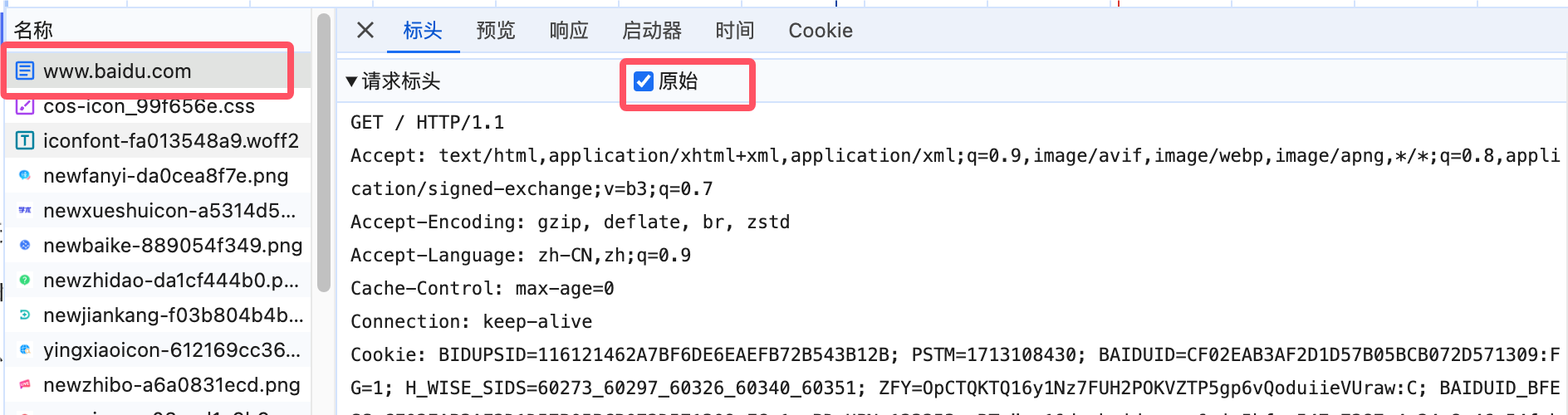
实际上HTTP请求头部包含请求行、请求头部、空行和请求数据四个部分组成,我们依次来介绍一下它们的作用:
-
请求行:首先就是请求方法(GET、POST、OPTION等)请求方法代表对服务器资源的不同操作,比如GET请求用于向服务器获取特定资源,POST请求用于向服务器提交数据,用于创建新资源或处理数据等。
接着是请求的资源URI,比如我们要访问某个页面下的子页面或是其他内容时,可以通过不同的URI地址来指定。
紧跟着的HTTP/1.1就是当前使用的HTTP版本,目前大部分网站采用的是HTTP/1.1版本,不同的HTTP版本有着一些差异,后续会进行介绍。
-
请求头:请求头中包含了客户端以及请求的很多信息,由一系列键值对组成,使用英文冒号进行分割,不同的键代表着不同的含义,比如Accept-Language表示客户端支持的语言类型,Host表示请求的主机名字(也就是网站地址)、User-Agent包含了当前浏览器的一些信息,有关详细的HTTP请求标头列表和含义,可以参阅:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers,后续课程中我们会详细认识一些重要的请求标头。
-
空行:仅用于分割请求头和请求体。
-
请求体:一些请求可能会包含一些要发送给服务端的数据,一般都通过请求体进行携带。比如我们网站上的登录请求,就需要发送给服务端我们的用户名和密码,此时就需要通过请求体携带,并且此时我们选择的请求方法也有一定的要求,一般提交数据都是使用POST请求而不是GET,GET虽然也可以携带请求体,但并不规范,甚至有些浏览器直接不支持。
看完了请求内容,我们接着再来看看响应内容,我们的浏览器向百度的服务器发送了一个页面请求之后,百度服务器会返回给我们一个最基本的页面文件:
可以看到这里面写了很多内容,这实际上是一个HTML文件,浏览器会自动解析并加载里面所有的内容,最后以网页的形式展示展示到浏览器中,这样我们就可以看到整个网站的内容了(有关HTML详细语法,我们会在前端课程中详细介绍)
同样的,作为服务端的响应报文也有头部信息:
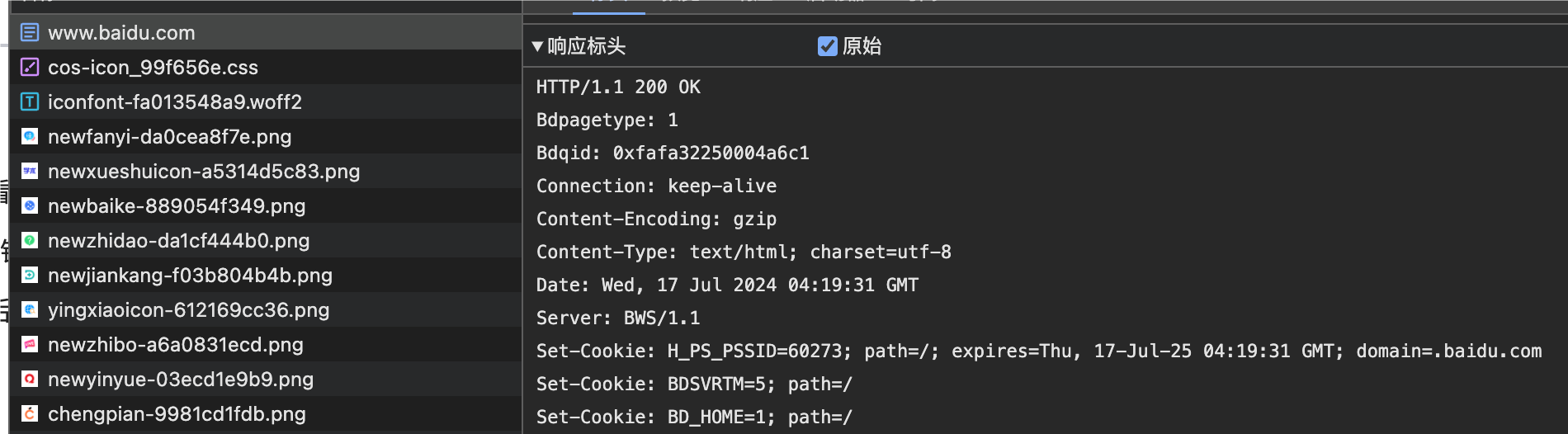
HTTP响应头部包含状态行、响应头、空行和响应体,我们来依次介绍一下:
- 状态行:和HTTP请求差不多,首先是服务端响应的HTTP版本,与请求中的相匹配。接着是一个非常重要的内容,状态码,状态码代表服务端处理本次请求的结果,一般正常响应就是200,如果遇到其他情况,会有不同的状态码,比如302、400、404、500等,我们会在后面详细介绍不同状态码的含义。状态码后面就是对返回的状态码的简单描述,比如200后的OK表示请求处理完全正常,很OK👌🏻
- 响应头:和请求头一样,包含诸多键值对,同时响应头中也有各种响应标头表示不同的含义,我们后面会认识一些比较重要的标头。
- 空行:仅用于分割响应头和响应体。
- 响应体:就是我们上面看到的响应内容了,一般就是页面内容或是我们后面会认识到的JSON数据。
相信各位小伙伴已经对HTTP协议有了一定的认识,我们接着来详细讨论一下HTTP版本以及状态码。也许小伙伴最先注意到的就是这个HTTP/1.1,它实际上是HTTP协议的版本,我们先从最初的版本开始介绍:
- **HTTP/0.9:**发布于1991年,这个版本只支持GET请求,且无状态,无头部信息,仅用于传输纯文本文件,由Tim Berners-Lee设计,功能非常有限,无法满足一些复杂需求。
- **HTTP/1.0:**发布于1996年,相比最初的版本增加了多种HTTP方法(如POST和HEAD)以及引入了HTTP头部,允许传输元数据,支持MIME类型,可以传输多种文件类型,缺点是默认每个连接只能为单个请求服务,请求完成后就会关闭连接,效率低,只能手动设置 Connection: keep-alive 请求头来实现连接复用。
-
**HTTP/1.1:**最终发布于1999年,在上一代的基础上进行了扩展和优化,引入了管线化、分块传输编码等特性,同时为了优化一次请求的利用效率,默认支持了持久连接,同一个TCP连接可复用以处理多个请求和响应,无需额外设置Connection: keep-alive请求头。虽然这个版本提升了一些性能,但由于在同一时间内只能处理一个请求,万一刚好有一个请求卡住了后面全部跟着卡,所以仍存在队头阻塞问题。
-
**HTTP/2:**发布于2015年,这个版本支持多路复用,即一个TCP连接现在可以并发处理多个请求和响应,解决了HTTP/1.1中的队头阻塞问题,此外,HTTP2还引入了头部压缩,提升传输效率、二进制分帧层,提升解析效率,以及允许服务器主动向客户端推送资源。
现在比较主流的网站基本都已经支持HTTP2协议访问了。
-
**HTTP/3:**发布于2022年,采用QUIC协议,QUIC协议是一种基于UDP协议的新型传输层协议,在这个版本之前,HTTP请求一律采用的是TCP协议进行交互,免不了三次握手和四次挥手带来的时间开销,而HTTP3基于UDP改进版QUIC协议,提供低延迟的连接建立和重传机制,完全解决了队头阻塞问题,提升了网络传输效率且内置加密,更加安全,是目前的主要发展方向。
我们接着来看常见的HTTP响应状态码:
- **1xx: 信息响应:**这类响应结果不是很常见
- 100 Continue: 服务器已接收请求头,客户端应继续发送请求主体。
- 101 Switching Protocols: 服务器同意切换协议。
- **2xx: 成功:**这类状态码基本都是请求成功。
- 200 OK: 请求成功,服务器已返回请求的数据。
- 201 Created: 请求已成功,并且服务器创建了新的资源。
- 202 Accepted: 服务器已接受请求,但尚未处理。
- 204 No Content: 请求成功但无返回内容。
- **3xx: 重定向:**这类状态码一般是用于告诉浏览器请求的站点已经被移动到其他地址了,需要更换到新的地址。
- 301 Moved Permanently: 请求的资源已被永久移动到新URL。
- 302 Found: 请求的资源临时被移动到新URL。
- 304 Not Modified: 资源未被修改,可以使用缓存的版本。
- **4xx: 客户端错误:**这类状态码在我们后续学习中会经常碰到,基本都是由于浏览器发送的请求少携带了什么数据或是请求有问题之类的。
- 400 Bad Request: 服务器无法理解请求的格式。
- 401 Unauthorized: 请求需要用户认证。
- 403 Forbidden: 服务器拒绝请求。
- 404 Not Found: 服务器找不到请求的资源。
- 405 Method Not Allowed: 请求方法被禁用。
- 429 Too Many Requests: 客户端在给定的时间内发送了太多请求。
- **5xx: 服务器错误:**这类状态码也会在外面后续学习中经常碰到,基本都是由于服务端出现错误导致的。
- 500 Internal Server Error: 服务器内部错误。
- 501 Not Implemented: 服务器不支持请求的功能。
- 502 Bad Gateway: 网关或代理服务器收到无效响应。
- 503 Service Unavailable: 服务器暂时无法处理请求(超负载或维护)。
- 504 Gateway Timeout: 网关或代理服务器未及时收到上游服务器的响应。
关于HTTP协议相关的内容,我们就介绍到这里,更多详细内容,我们会在后面的教学中继续为大家讲解。接下来我们会先从Java网络编程开始,带大家逐步走进我们的Web服务端开发。
Java网络编程
通过上一部分,我们了解了丰富的网络世界存在着各种各样的通信协议,要实现两台计算机互相发送数据,就必须要按照一定的规则进行数据的发送和接受,而Java早已为我们封装好了相应的API接口,我们只需要直接使用即可轻松实现网络通信。
了解Socket技术
我们可以通过Socket技术(它是计算机之间进行通信的一种约定或一种方式),实现两台计算机之间的通信,Socket也被翻译为套接字,是操作系统底层提供的一项通信技术,它支持TCP和UDP。而Java就对Socket底层支持进行了一套完整的封装,我们可以通过Java来轻松实现Socket通信。
要实现Socket通信,我们必须创建一个数据发送者和一个数据接收者,也就是客户端和服务端,我们需要提前启动服务端,来等待客户端的连接,而客户端只需要随时启动去连接服务端即可,它们默认采用的是TCP协议进行连接。
首先编写服务端,服务端使用ServerSocket对象来实现,它代表我们的Socket服务端,还记得我们之前说过每个应用程序都需要一个端口来进行TCP通信吗,我们可以为其绑定一个用于通信的端口以便客户端可以进行连接:
ServerSocket server = new ServerSocket(8080) //参数为绑定的端口,之后一律使用此端口进行通信创建好后,由于服务端会一直占用资源,我们在使用完成后也需要对其资源进行释放,和之前IO一样,这里我们直接使用try-with-resource语法来编写:
try(ServerSocket server = new ServerSocket(8080)) {
} catch (IOException e) {
e.printStackTrace();
}接着,我们可以调用accept()方法来监听客户端连接,如果没有客户端连接,程序会阻塞在此位置等待连接:
try(ServerSocket server = new ServerSocket(8080)) {
server.accept(); //等待客户端连接
} catch (IOException e) {
e.printStackTrace();
}当客户端连接到来后,accept()方法会返回应该Socket对象作为结果,它代表一个客户端Socket连接,我们可以打印看看客户端连接的相关信息:
Socket socket = server.accept();
System.out.println("接受到来自客户端的连接: " + socket.getInetAddress() + ":" + socket.getPort());接着就是编写客户端了,我们可以使用Socket对象来完成,其中参数分别是服务端地址和端口,这里我们因为是本地启动的服务端,相当于连接自己,所以说直接使用我们本机的IP即可:
Socket socket = new Socket("localhost", 8080) //填写连接服务端的信息各位小伙伴可以尝试输入一下ipconfig命令查看网络列表,这里解释一下localhost、192.168.x.x、127.0.0.1的区别:
所有计算机都有一个特殊的网络和IP地址,127.0.0.1,它被称作是本地环回地址,我们访问此IP地址等于访问这台电脑自己,这个地址主要用于本地主机和本地服务之间的通信,所以说如果我们要访问自己电脑上的服务端,只需要填写这个IP地址即可。
那这个跟我们从路由器得到的IP地址有什么区别吗,路由器得到的192.168.XX.XX是路由器为我们分配的一个局域网地址,使用自己的地址同样可以代表这台计算机本身,但是当我们切换网络时,局域网地址可能会出现变化,所以说它不适合作为本地连接的IP地址使用。
localhost实际上是一个域名,但是它等价于127.0.0.1,操作系统自带的域名解析(通过本地主机文件hosts实现)可以将其自动解析到127.0.0.1上,所以说很多时候我们使用localhost也可以代表本地主机。但是注意,在我们之后学习Web服务器时,浏览器会将它们认为是两个不同的站点。
当Socket对象创建时,就会自动进行连接了:
try (Socket socket = new Socket("localhost", 8080)){
System.out.println("已连接到服务端!");
}catch (IOException e){
e.printStackTrace();
}现在我们先启动一下服务端接着再启动客户端,此时就可以完成连接了:

注意客户端不需要指定自己的端口,一般都是自动分配,所以说我们收到来自客户端的连接时一般都是一个随机的端口号,然后前面的IP地址就是客户端用于访问我们服务端的IP地址,如果各位小伙伴使用局域网IP地址访问的话,这里会出现一些变化哦。
各位小伙伴也可以试试看同一个WIFI下,在同学电脑上启动服务端,自己电脑上启动客户端,让客户端尝试连接另一个主机IP地址上的服务器,如果能成功说明你已经明白网络的基本使用了。
使用Socket进行数据传输
前面我们介绍了如何使用Socket创建网络连接,接着我们来试试看使用Socket进行数据传输。
要进行数据传输非常简单,我们可以通过Socket直接获得一个输入流和输出流,这跟我们之前在JavaSE中学习的用法是完全一样的,所以说基本没有任何压力,直接开写:
Socket socket = server.accept();
System.out.println("接受到来自客户端的连接: " + socket.getInetAddress() + ":" + socket.getPort());
//使用while不断读取来自客户端的数据
InputStream stream = socket.getInputStream();
int len = 0;
byte[] buffer = new byte[1024];
while ((len = stream.read(buffer)) > 0) { //当客户端没有数据发送时,read会处于阻塞状态
System.out.println("接受到客户端数据: " + new String(buffer, 0, len));
}客户端这边我们就不断读取控制台输入内容,不断向服务端发送数据:
try (Socket socket = new Socket("localhost", 8080);
Scanner scanner = new Scanner(System.in)) {
System.out.println("已连接到服务端,请输入要发送的数据: ");
//不断向输出流中输入数据
OutputStream stream = socket.getOutputStream();
while (true) {
String str = scanner.nextLine();
stream.write(str.getBytes());
}
}catch (IOException e){
e.printStackTrace();
}和之前一样,我们启动一下服务端和客户端来试试看吧:

这样我们就成功实现了向服务端发送数据,现在我们让服务端也向客户端发送数据看看,比如客户端发送完数据之后,服务端会给一个回复,说收到了数据,我们可以像这样编写服务端:
InputStream in = socket.getInputStream();
OutputStream out = socket.getOutputStream();
int len;
byte[] buffer = new byte[1024];
while ((len = in.read(buffer)) > 0) { //当客户端没有数据发送时,read会处于阻塞状态
System.out.println("接受到客户端数据: " + new String(buffer, 0, len));
out.write(("已收到长度为 " + len + " 字节的数据").getBytes()); //将响应内容写入到输出流
}在客户端这边,同样在发送完数据后阻塞读取一次数据:
//阻塞读取响应内容
int len;
byte[] buffer = new byte[1024];
len = in.read(buffer);
System.out.println(new String(buffer, 0, len));现在当客户端发送数据后,服务端就会实时响应结果给客户端,实现消息互相发送:

除了发送消息之外,有了输入输出流,即使是文件传输也不在话下,我们可以来编写一个文件传输程序,让客户端传输文件到服务端去:
try(ServerSocket server = new ServerSocket(8080)) {
Socket socket = server.accept();
System.out.println("接受到来自客户端的连接准备开始进行文件传输");
InputStream in = socket.getInputStream();
FileOutputStream stream = new FileOutputStream("test");
long len, total = 0;
byte[] buffer = new byte[1024];
while ((len = in.read(buffer)) > 0) {
System.out.println("正在进行文件传输,当前已接收: " + total + " 字节数据");
stream.write(buffer, 0, (int) len);
total += len;
}
} catch (IOException e) {
e.printStackTrace();
}try (Socket socket = new Socket("localhost", 8080);
Scanner scanner = new Scanner(System.in)) {
System.out.println("已连接到服务端,请输入要发送的文件路径: ");
OutputStream out = socket.getOutputStream();
FileInputStream stream = new FileInputStream(scanner.nextLine());
stream.transferTo(out);
} catch (IOException e) {
e.printStackTrace();
}各位小伙伴同样可以试试看从一台电脑发送文件到另一台电脑上。
Socket实现UDP通信
我们接着来看如何使用Socket实现UDP通信,Java为我们提供了DatagramSocket API,它是一种UDP Socket,用于发送和接收UDP数据报。
由于UDP不像TCP那样需要提前连接,所以我们只需要创建一个Socket等待数据到来即可:
try(DatagramSocket socket = new DatagramSocket(8080)) { //绑定8080端口
} catch (IOException e) {
e.printStackTrace();
}接着我们即可连续读取客户端发来的数据:
while(true) {
//UDP数据包,类似于数据缓冲区,数据会先被缓存到里面
DatagramPacket packet = new DatagramPacket(new byte[1024], 1024);
socket.receive(packet); //将收到的数据缓冲到DatagramPacket中
System.out.println(new String(packet.getData())); //取出数据并打印
}客户端这边由于不需要预先建立连接,所以我们直接创建一个UDP数据包,并在数据包中指定发送的IP地址和端口等内容,发送后直接就可以到达:
try (DatagramSocket socket = new DatagramSocket();
Scanner scanner = new Scanner(System.in)) {
while (true) {
String str = scanner.nextLine();
byte[] data = str.getBytes();
InetAddress address = InetAddress.getByName("127.0.0.1"); //直接在数据包中填写要发送到的目标主机IP地址和端口信息
DatagramPacket packet = new DatagramPacket(data, data.length, address, 8080);
socket.send(packet);
}
} catch (IOException e){
e.printStackTrace();
}这个相比TCP就简单很多了,直接发送就能收到:

这里简单介绍了一下UDP通信。
使用浏览器访问Socket服务器
最后我们来研究一下HTTP协议,我们前面说过,浏览器访问一个网站实际上用的就是HTTP协议,并且HTTP协议是基于TCP协议的,所以说我们可以创建一个ServerSocket来处理浏览器的访问请求,看看HTTP请求到底长啥样。首先我们还是直接编写一个服务端来等待连接:
try(ServerSocket server = new ServerSocket(8080)){
Socket socket = server.accept();
InputStream in = socket.getInputStream();
while (!socket.isClosed()) {
int i = in.read();
if(i == -1) break;
System.out.print((char) i);
}
}catch (IOException e){
e.printStackTrace();
}此时我们使用Chrome浏览器访问:http://localhost:8080,可以直接在服务端收到以下数据:

这正是我们之前说的HTTP协议对应的报文格式,可以看到当我们使用浏览器访问服务端时,浏览器会默认向我们的服务端发送一个GET请求,路径为根路径"/",并且还包含了很多请求标头。
但是此时我们会发现,浏览器会一直处于加载中状态:

这是因为HTTP规定请求完成之后服务端需要给一个响应结果,所以说浏览器实际上一直在等待我们的服务端发送一个请求结果给它,但是我们这里没有做任何处理,所以说就会一直卡住。
现在我们来尝试给它返回一个简单的HTML页面(看不懂代码没关系,这里只是测试一下)
try(ServerSocket server = new ServerSocket(8080)){
Socket socket = server.accept();
OutputStreamWriter writer = new OutputStreamWriter(socket.getOutputStream());
String html = """
<!DOCTYPE html>
<html lang="en">
<head>
<title>测试网站</title>
</head>
<body>
<h1>欢迎访问我们的测试网站</h1>
<p>这个网站包含很多你喜欢的内容,但是没办法展示出来,因为我们还没学会</p>
</body>
""";
writer.write("HTTP/1.1 200 OK\r\n"); //根据HTTP协议规范,返回对应的响应格式
writer.write("Content-Type: text/html;charset=utf-8\r\n"); //务必加一下内容类型和编码,否则会乱码
writer.write("\r\n");
writer.write(html);
writer.flush();
}catch (IOException e){
e.printStackTrace();
}此时我们使用Chrome浏览器再次访问服务端,就可以展示出我们返回的数据了:
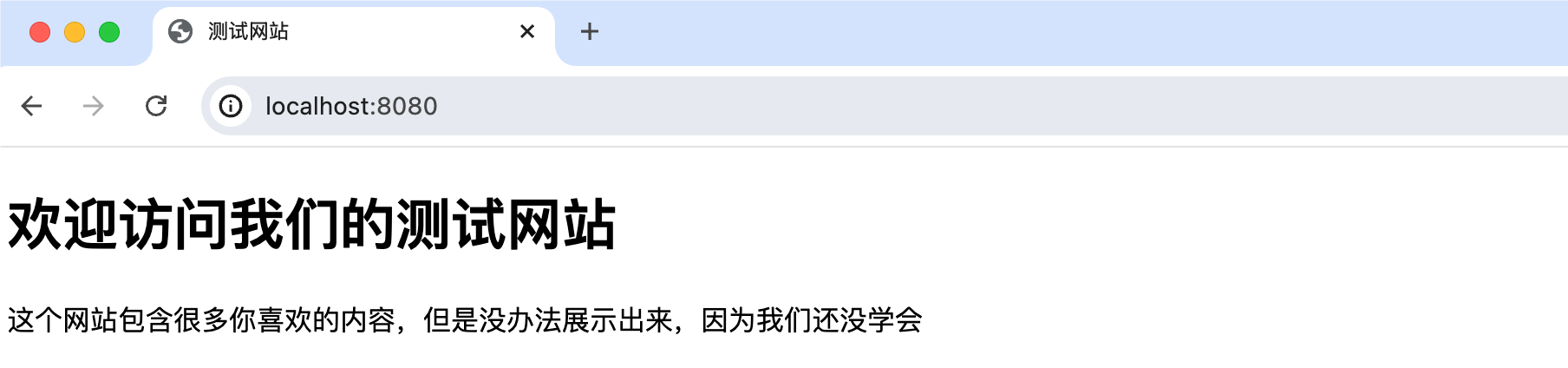
是不是感觉非常神奇,只需要返回给浏览器一个HTML代码,就成功以网站的形式打开了。这也是我们后续学习的主要方向,只不过使用Socket这种框架来编写网站,太过于原始了,尤其是对HTTP协议报文的处理上,自己写太过麻烦了,后面我们会学习各种Web服务端,它们是专用于网站服务器的程序,我们就能快速编写更加高级的Web应用程序。