
Java与数据库
在开始本章节之前,需要先完成以下前置课程学习:
- 《MySQL数据库技术》了解如何使用MySQL存储数据以及对数据的增删改查操作。
注意: 请务必完成前置课程学习,本章节默认各位已经完成前置课程学习,不会再对已讲解内容重复介绍。
前面我们学习了MySQL数据库以及编写各种SQL语句对数据库进行操作,那么如何通过Java如何去使用数据库来帮助我们存储数据呢,这将是本章节讨论的重点。
JDBC操作数据库
JDBC是什么?JDBC英文名为:Java Data Base Connectivity(Java数据库连接)官方解释它是Java编程语言和广泛的数据库之间独立于数据库的连接标准的Java API,根本上说JDBC是一种规范,它提供的接口,一套完整的,允许便捷式访问底层数据库。可以用JAVA来写不同类型的可执行文件:JAVA应用程序、JAVA Applets、Java Servlet、JSP等,不同的可执行文件都能通过JDBC访问数据库,又兼备存储的优势。简单说它就是Java与数据库的连接的桥梁或者插件,用Java代码就能操作数据库的增删改查、存储过程、事务等。
我们可以发现,JDK自带了一个java.sql包,而这里面就定义了大量的接口,不同类型的数据库,都可以通过实现此接口,编写适用于自己数据库的实现类。而不同的数据库厂商实现的这套标准,我们称为数据库驱动。
准备工作
那么我们首先来进行一些准备工作,以便开始JDBC的学习:
- 配置IDEA或Navicat连接到我们的数据库,以便以后调试
- 创建一个新的用于学习的数据库
- 将mysql驱动jar依赖导入到项目中(推荐6.0版本以上,这里用到是8.0)
一个Java程序并不是一个人的战斗,我们可以在别人开发的基础上继续向上开发,其他的开发者可以将自己编写的Java代码打包为jar,我们只需要导入这个jar作为依赖,即可直接使用别人提供的代码,这样就不需要我们自己从头开始手撕了,就像我们直接去使用JDK提供的类一样。
首先选择项目结构:

接着添加一个新的库:
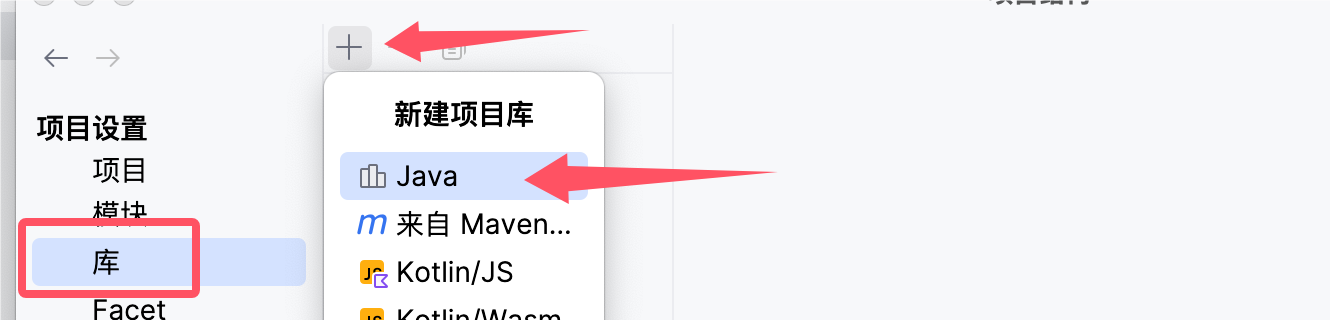
这样我们就成功将库引入了,可以在外部库栏目中看到我们引入的jar包:

使用JDBC连接数据库
现在我们已经成功引入了MySQL数据库驱动,接着就可以正式开始使用JDBC了。在开始之前可以先打印一下看看自己的依赖是否成功引入了:
public static void main(String[] args) {
//DriverManager是管理数据库驱动的工具类,我们可以通过它来查看当前已经引入的驱动列表
DriverManager.drivers().forEach(System.out::println);
}正常情况下这里应该会打印MySQL的驱动类:

要访问一个数据库,第一步肯定是创建一个新的的连接,我们可以通过DriverManager来创建一个新的数据库连接:
//使用getConnection方法来创建一个新的连接
try (Connection connection = DriverManager.getConnection("连接URL","用户名","密码")){
} catch (SQLException e) {
e.printStackTrace();
}这里最主要的就是连接数据库的URL,还记得我们在上一章介绍的网站URL吗,格式为 <协议>://<主机>:<端口>/<路径>,互联网上所有的资源,都有一个唯一确定的URL,而MySQL本身也是以一个服务端的形式运行的,我们要连接也需要对应的URL才可以:
jdbc:mysql://localhost:3306/study接着我们需要创建一个用于执行SQL的Statement对象,然后就可以像在命令行中那样直接使用SQL命令了:
try (Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/study","root","123456");
Statement statement = connection.createStatement()){
//使用executeQuery来执行一个查询SQL语句
ResultSet set = statement.executeQuery("select * from user"); //选择user表全部内容
} catch (SQLException e) {
e.printStackTrace();
}这里我们会得到一个ResultSet对象,我们使用它来获取查询结果,它类似于迭代器,需要使用next来向下迭代,但是使用上会有一些小小的区别:
ResultSet set = statement.executeQuery("select * from user");
while (set.next()) { //使用next开始读取查询结果的下一行
System.out.print(set.getInt("id") + " "); //直接获取本行指定字段下的数据
System.out.print(set.getString("name") + " ");
System.out.println(set.getInt("age"));
}是不是感觉非常简单?接下来我们会为各位小伙伴详细介绍这里用到的几个类。
了解DriverManager
我们首先来了解一下DriverManager是什么东西,它其实就是管理我们的数据库驱动的。
我们知道,要操作数据库,需要通过DriverManager.getConnection创建连接,而开始连接之前,JDBC会自动扫描我们所有引入的数据库驱动并进行加载,此时会调用registerDriver方法完成对Driver接口实现类的加载:
public static void registerDriver(java.sql.Driver driver, DriverAction da)
throws SQLException {
/* Register the driver if it has not already been added to our list */
if (driver != null) {
registeredDrivers.addIfAbsent(new DriverInfo(driver, da));
} else {
// This is for compatibility with the original DriverManager
throw new NullPointerException();
}
println("registerDriver: " + driver);
}这里我们提到,系统会自动发现Driver接口的实现类并加载,这实际上是一种SPI机制:
Java的SPI(Service Provider Interface)机制是一种服务发现机制,它允许通过接口来加载服务实现。SPI通常用于在框架或库中提供可插拔的功能,使得不同的实现可以被动态加载和使用。这个机制在Java的标准库中以及许多开源项目中得到了广泛应用。
我们之前多多少少接触到过API的概念,实际上我们使用的很多类都是一种API,比如集合类,我们使用的往往是其接口,我们不需要关心其具体实现内容,我们只需要知道接口定义某个方法的用途,按照接口的定义去使用即可。
而SPI则来到了另一侧,也就是接口定义了这些操作,我们需要去实现接口定义的这些操作,这样才可以使得这个功能可以实实在在地使用。
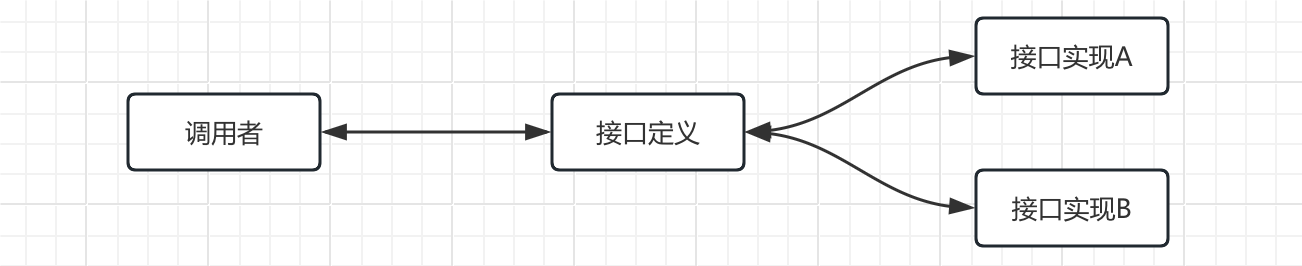
因此,我们这里使用的MySQL数据库驱动,其实就是对JDBC官方定义的接口的一种实现,利用SPI机制就可以完成加载(实际上在META-INF/services目录下有记录),只不过这个加载过程比较复杂,我们就不深究了。
当数据库驱动加载完成之后,才可以继续完成数据库连接的建立,因为我们上一节的实例代码中直接就使用了getConnection创建连接,我们可以来观察一下getConnection做了什么:
@CallerSensitive
public static Connection getConnection(String url,
String user, String password) throws SQLException {
java.util.Properties info = new java.util.Properties();
//这里判断的是数据库用户名和密码是否填写
if (user != null) {
info.put("user", user);
}
...
//接着会调用内部的私有getConnection方法
return (getConnection(url, info, Reflection.getCallerClass()));
}private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException {
//这里需要通过调用此方法的类来获取其类加载器,便于后续加载数据库驱动
ClassLoader callerCL = caller != null ? caller.getClassLoader() : null;
if (callerCL == null || callerCL == ClassLoader.getPlatformClassLoader()) {
callerCL = Thread.currentThread().getContextClassLoader();
}
//检查数据库连接的url是否为空,如果是直接报错
if (url == null) {
throw new SQLException("The url cannot be null", "08001");
}
...
//这一步用于确保数据库驱动已经全部加载,包括上面在一开始说的数据库驱动加载部分
ensureDriversInitialized();
// 遍历所有已经加载的驱动,然后有合适的就可以直接建立连接了
SQLException reason = null;
for (DriverInfo aDriver : registeredDrivers) {
// 如果调用此方法的Class有权限加载并使用当前驱动,就可以开始创建连接了
if (isDriverAllowed(aDriver.driver, callerCL)) {
try {
...
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// 如果连接不为空,则创建成功,这里直接就返回了
...
return (con);
}
} catch (SQLException ex) ...
} else ...
}
// 如果代码走到这里那肯定是出问题了,要是一个能连接的驱动都没找到,直接报错
if (reason != null) {
println("getConnection failed: " + reason);
throw reason;
}
...
}我们看到实际上在源代码中,有很多地方都会打印日志,为什么到使用的时候就没有了呢?
public static void println(String message) {
synchronized (logSync) {
if (logWriter != null) { //注意这里需要logWriter不为null才能打印
logWriter.println(message);
...
}
}
}所以,如果需要打印日志的话,我们给它设置一个logWriter即可:
DriverManager.setLogWriter(new PrintWriter(System.out));这样我们就可以在控制台看到日志打印信息了:
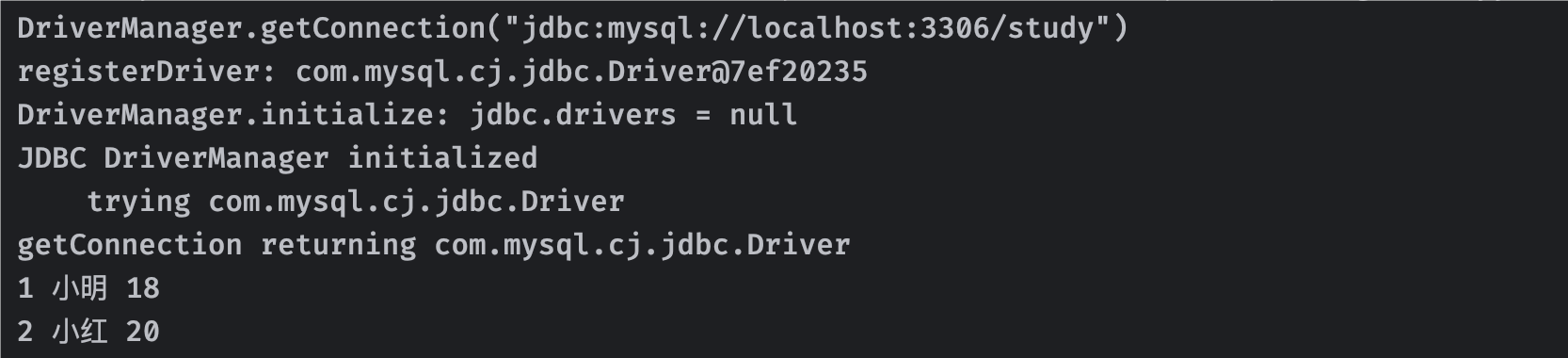
下一部分我们接着来介绍Connection和Statement。
了解Connection和Statement
Connection是数据库的连接对象,也可以称作是一次会话,它可以执行 SQL 语句并在连接上下文中返回结果,这在我们一开始的时候就已经尝试过了。
Connection对象中也包含数据库相关的一些信息,当我们连接成功后,可以通过getMetaData来获取数据库信息对象:
DatabaseMetaData meta = connection.getMetaData();
System.out.println("数据库名称: " + meta.getDatabaseProductName());
System.out.println("数据库版本: " + meta.getDatabaseMajorVersion() + "." + meta.getDatabaseMinorVersion());
System.out.println("当前用户: " + meta.getUserName());
System.out.println("数据库驱动: " + meta.getDriverName());
System.out.println("数据库驱动版本: " + meta.getDriverMajorVersion() + "." + meta.getDriverMinorVersion());
System.out.println("数据库驱动: " + meta.getCatalogTerm());我们也可以使用Connection对象获取一些连接上的信息,比如:
System.out.println("当前选择的数据库: " + connection.getCatalog());System.out.println("数据库超时时间: " + connection.getNetworkTimeout() + "ms");// 不支持 = 0
// 读未提交 = 1
// 读已提交 = 2
// 可重复读 = 4
// 序列化 = 8
System.out.println("事务隔离级别: " + connection.getTransactionIsolation());我们接着来看Statement对象,它是我们执行SQL语句的关键,它用于执行静态 SQL 语句并返回其生成结果的对象。
ResultSet set = statement.executeQuery("select * from user");可以看到这里我们使用executeQuery方法来查询了表中所有数据,除了这个方法之外,Statement还提供了用于各种DML和DQL以及批处理等操作的方法,我们会在下节中为大家逐步介绍。
执行DQL和DML操作
还记得我们在MySQL中学习的DQL和DML操作吗?它们是用于向数据库中查询、插入、删除和更新数据的操作,包括SELECT、UPDATE、INSERT、DELETE,我们首先从最简单的SELECT语句开始。
前面我们介绍了Statement对象,它为我们提供了很多方法用于执行SQL语句,其中executeQuery就是用于执行SELECT查询语句的,我们来看看它的使用方式,它在接口中是这样定义的:
//执行给定的 SQL 语句,该语句返回单个 ResultSet 对象。
ResultSet executeQuery(String sql) throws SQLException;这里在执行完SQL语句后,会返回一个ResultSet对象作为结果,它表示一个数据库结果集的数据表,通常通过执行查询数据库的语句来生成。
使用起来也很简单,类似于迭代器:
//一开始的位置为第0行,读取第一行数据要先调用一次next
set.next();
从0开始,每次需要查询下一行数据前都要执行一次next方法,接着我们可以使用各种get方法来获取当前行的数据,比如我们要获取当前这一行的name字段值:
set.next();
System.out.println(set.getString("name"));查询结果为:

注意: 如果使用列序号读取数据,列的下标是从1开始的。
但是,如果我们使用Statement在执行完一次executeQuery得到ResultSet后,再次执行一次查询,那么之前得到的ResultSet在读取时会出现错误:
默认情况下,每个Statement对象只能同时打开一个ResultSet对象。因此,如果一个ResultSet对象的读取与另一个对象的读取交错,则每个对象都必须由不同的Statement对象生成。如果存在打开的语句的当前对象,则Statement接口中的所有执行方法都会隐式关闭语句的当前ResultSet对象。
ResultSet set = statement.executeQuery("select * from user order by id desc");
ResultSet set2 = statement.executeQuery("select * from user order by id desc");
set.next();
System.out.println(set.getString("name"));得到错误:

我们接着来看DML操作,Statement为我们提供executeUpdate方法:
//执行给定的 SQL 语句,该语句可以是 、 UPDATE或DELETE语句,也可以是INSERT不返回任何内容的 SQL 语句,例如 SQL DDL 语句
int executeUpdate(String sql) throws SQLException;
//当返回的行计数可能超过 Integer. MAX_VALUE时,应使用此方法。
long executeLargeUpdate(String sql) throws SQLException这里返回的结果是一个int类型值,它代表:
- SQL 数据操作语言 (DML) 语句执行生效的行计数。
- 不返回任何内容的 SQL 语句,并且会直接得到 0 作为结果。
我们从insert语句开始,看看是如何使用的:
int i = statement.executeUpdate("insert into user (name, age) values ('小明', 18)");
System.out.println("生效行数: " + i);
实际上用起来感觉和我们在命令行直接执行SQL语句差不多。
除了我们上面提到的executeUpdate和executeQuery方法外,还有一个普通的execute方法:
// 执行给定的 SQL 语句,该语句可能会返回多个结果。
boolean execute(String sql) throws SQLException;注意这个方法返回的结果是一个布尔类型结果,这个结果:
- 如果第一个结果是 ResultSet 对象,返回true
- 如果它是更新计数或没有结果,返回false
也就是说,如果我们执行完SQL语句返回的是一个ResultSet结果集对象,那么就是真,也就是说只有选择语句才可以得到结果集,其他的DML语句是不可能得到这个结果的,所以肯定是假。因此,这个方法一般用于我们不确定传入的SQL语句到底是DQL还是DML语句的时候使用。
boolean result = statement.execute("select * from user");
System.out.println(result ? "存在结果集" : "不存在结果集");如果我们执行的是一个DQL语句,那么这里会得到结果集,结果集可以通过getResultSet方法获取:
statement.execute("select * from user");
ResultSet set = statement.getResultSet(); //主动获取ResultSet
while (set.next()) {
System.out.println(set.getString("name"));
}如果我们执行的时一个DML语句,那么这里会返回false,更新生效的行数可以通过getUpdateCount方法获取:
statement.execute("update user set name = '小明' where id = 1");
System.out.println(statement.getUpdateCount());这样,关于数据库的基本操作就介绍完毕了。
批处理操作
我们接着来看批处理操作,当我们要执行很多条语句时,大家可能会一个一个地提交:
//现在要求把下面所有用户都插入到数据库中
List<String> users = List.of("小刚", "小强", "小王", "小美", "小黑子");
//使用for循环来一个一个执行insert语句
for (String user : users) {
statement.executeUpdate("insert into user (name, age) values ('" + user + "', 18)");
}虽然这样看似非常完美,也符合逻辑,但是实际上我们每次执行SQL语句,都像是去厨房端菜到客人桌上一样,我们每次上菜的时候只从厨房端一个菜,效率非常低,但是如果我们每次上菜推一个小推车装满N个菜一起上,效率就会提升很多,而数据库也是这样,我们每一次执行SQL语句,都需要一定的时间开销,但是如果我把这些任务合在一起告诉数据库,效率会截然不同:

那么如何才能一口气全部交给数据库处理呢,最简单的方式是直接对我们的SQL语句进行优化,我们可以直接拼接出这样的一个字符串出来,只需要执行一次SQL即可:
INSERT INTO user (name, age) VALUES
('小刚', 18),
('小强', 18),
('小王', 18),
('小美', 18),
('小黑子', 18);但是有些时候很难实现对SQL语句的优化,我们也可以使用批处理来完成:
List<String> users = List.of("小刚", "小强", "小王", "小美", "小黑子");
for (String user : users) {
//使用addBatch将一个SQL语句添加到批处理列表中
statement.addBatch("insert into user (name, age) values ('" + user + "', 18)");
}
int[] results = statement.executeBatch(); //统一执行批处理
System.out.println(Arrays.toString(results));我们可以使用addBatch方法来将任务添加到批处理队列中,所有任务添加完成后,再使用executeBatch一次性执行批处理操作,这样同样可以防止多次提交SQL命令。
并且这里会返回一个int数组代表每一个操作受影响的行数。
将查询结果映射为对象
现在我们从数据库中查询每条记录了,但是我们现在查询得到的数据依然是零零散散的,有没有更好的办法可以集中管理数据呢?实际上各位小伙伴不难发现,数据库中某一张表的一条记录,正好就是我们Java中某一个对象实体所包含的信息,而我们之前在设计数据库表的时候,也是这样去参考的:
1 小明 18public class User {
private int id;
private String name;
private int age;
}因此,为了方便,我们在查询到数据之后,一般会将每条记录都创建为一个对应的实体类对象。
我们接着来完善一下它:
public class User {
...
public User(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public void say(){
System.out.println("我叫:" + name + ",编号为:" + id + ",我的年龄是:" + age);
}
}好了,我们现在就可以在查询数据的时候直接转换为我们的实体类对象了:
while (set.next()) {
User user = new User(set.getInt("id"),
set.getString("name"),
set.getInt("age"));
user.say();
}
只不过普通的类型对于我们操作不太方便,比如我们想要获取对象的一些数据,还需要额外编写对应的getter方法,为了方便,我们可以使用Java17新增的记录类型来编写,这是专用于数据表示的特殊类型,它在编译时自带了我们实体类封装所需要的getter方法,以及对应的比较方法重写,包括toString等,这样就不需要我们自己去编写了:
public record User(int id, String name, int age) {
public void say(){
System.out.println("我叫:" + name + ",编号为:" + id + ",我的年龄是:" + age);
}
}效果和之前完全一样,并且我们可以直接使用它自动生成的方法:
User user = new User(set.getInt("id"),
set.getString("name"),
set.getInt("age"));
System.out.println(user);
是不是感觉很方便?当然,除了使用Java17提供的记录类型之外,后面我们还会学习Lombok,它相比记录类型更加灵活和强大,利用注解同样可以在编译期完成对应方法的生成。
(选学)利用反射和泛型,直接得到对应的实体类,无需硬写类型:
private static <T> T convert(ResultSet set, Class<T> clazz){
try {
Constructor<T> constructor = clazz.getConstructor(clazz.getConstructors()[0].getParameterTypes()); //默认获取第一个构造方法
Class<?>[] param = constructor.getParameterTypes(); //获取参数列表
Object[] object = new Object[param.length]; //存放参数
for (int i = 0; i < param.length; i++) { //是从1开始的
object[i] = set.getObject(i+1);
if(object[i].getClass() != param[i])
throw new SQLException("错误的类型转换:"+object[i].getClass()+" -> "+param[i]);
}
return constructor.newInstance(object);
} catch (ReflectiveOperationException | SQLException e) {
e.printStackTrace();
return null;
}
}实际上,在后面我们会学习Mybatis框架,它对JDBC进行了深层次的封装,而它就进行类似上面反射的操作来便于我们对数据库数据与实体类的转换。